«Управление и Оптимизация Производственного Предприятия»
|
|
|
|
|
М.: Издательство «Экзамен», 2004. 3.4.5. Статистика нечетких множеств Нечеткие множества – частный вид объектов нечисловой природы. Поэтому при обработке выборки, элементами которой являются нечеткие множества, могут быть использованы различные методы анализа статистических данных произвольной природы - расчет средних, непараметрических оценок плотности, построение диагностических правил и т.д. Среднее значение нечеткого множества. Однако иногда используются методы, учитывающие специфику нечетких множеств. Например, пусть носителем нечеткого множества является конечная совокупность действительных чисел {x1, x2, ..., xn}. Тогда под средним значением нечеткого множества иногда понимают число. А именно, среднее значение нечеткого множества определяют по формуле:
где Очевидно, наряду с М(А) может оказаться полезным использование эмпирических средних, определяемых (согласно статистике в пространствах общей природы) путем решения соответствующих оптимизационных задач. Для конкретных расчетов необходимо ввести то или иное расстояние между нечеткими множествами. Расстояния в пространствах нечетких множеств. Как известно, многие методы статистики нечисловых данных базируются на использовании расстояний (или показателей различия) в соответствующих пространствах нечисловой природы. Расстояние между нечеткими подмножествами А и В множества Х = {x1, x2, …, xk} можно определить как
где
(Примем это расстояние равным 0, если функции принадлежности тождественно равны 0.) В соответствии с аксиоматическим подходом к выбору расстояний (метрик) в пространствах нечисловой природы разработан обширный набор систем аксиом, из которых выводится тот или иной вид расстояний (метрик) в конкретных пространствах, в том числе в пространствах нечетких множеств (см. главу 1.1). При использовании вероятностных моделей расстояние между случайными нечеткими множествами (т.е. между случайными элементами со значениями в пространстве нечетких множеств) само является случайной величиной, имеющей в ряде постановок асимптотически нормальное распределение [28]. Проверка гипотез о нечетких множествах. Пусть ответ эксперта – нечеткое множество. Естественно считать, что его ответ, как показание любого средства измерения, содержит погрешности. Если есть несколько экспертов, то в качестве единой оценки (группового мнения) естественно взять эмпирическое среднее их ответов. Но возникает естественный вопрос: действительно ли все эксперты измеряют одно и то же? Может быть, глядя на реальный объект, они оценивают его с разных сторон? Например, на научную статью можно смотреть как с теоретической точки зрения, как и с прикладной, и соответствующие оценки будут скорее всего различны (если они совпадают, то работа либо никуда не годится, либо является выдающейся). Итак, возник вопрос: как проверить согласованность мнений экспертов? Надо сначала определить понятие согласованности. Пусть А – нечеткий ответ эксперта. Будем считать, что соответствующая функция принадлежности есть сумма двух слагаемых:
где N(A) – «истинное» нечеткое множество, а ξA(u) – «погрешность» эксперта как прибора. Естественно рассмотреть две постановки. Мнения экспертов А(1), А(2), …, А(m) будем считать согласованными, если N(А(1)) = N(А(2)) = …, N(А(m)). Рассмотрим две группы экспертов. В первой у всех «истинное» мнение N(A), а во второй у всех - N(В). Две группы будем считать согласованными по мнениям, если N(A) = N(В). Согласованность определена. Как же ее проверить? Если экспертов достаточно много, то эти гипотезы можно проверять отдельно для каждого элемента множества – общего носителя нечетких ответов. Проверка последней гипотезы переходит в проверку однородности двух независимых выборок (глава 3.1). Здесь ограничимся постановками основных гипотез (ср. с аналогичными гипотезами, рассмотренными выше для люсианов). Восстановление зависимости между нечеткими переменными. Рассмотрим две нечеткие переменные А иВ. Пусть каждый из n испытуемых выдает в ответ на вопрос два нечетких множества Ai и Bi, i = 1, 2, …, n. Необходимо восстановить зависимость В от А, другими словами, наилучшим образом приблизить В с помощью А. Для иллюстрации основной идеи ограничимся парной линейной регрессией нечетких множеств. Нечеткое множество С назовем линейной функцией от нечеткого множества А, если для любого х из носителя А функции принадлежности множеств А и С таковы, что µС(х) = µА(у) при х = αу + β. Другими словами, µС(х) = µА((х - β)/α) для любого х из носителя А. В таком случае естественно писать С = αА +β. Однако нечеткие переменные, как и привычные статистикам числовые переменные, обычно несколько отклоняются от линейной связи. Наилучшее линейное приближение нечеткой переменной В с помощью линейной функции от нечеткой переменной А естественно искать, решая задачу минимизации по α, β расстояния от В до С. Пусть ρ(В, α0А + β0) = min ρ(B, αA + β), где ρ – некоторое расстояние между нечеткими множествами, а минимизация проводится по всем возможным значениям α и β. Тогда наилучшей линейной аппроксимацией В является α0А + β0. Если рассматриваемый минимум равен 0, то имеет место точная линейная зависимость. Для восстановления зависимости по выборочным парам нечетких переменных естественно воспользоваться подходом, развитым в статистике в пространствах произвольной природы для параметрической регрессии (аппроксимации). В соответствии с рассмотрениями главы 2.2.3 в качестве наилучших оценок параметров линейной зависимости следует рассматривать
Тогда наилучшим линейным приближением В является С* = α*А + β*. Вероятностно-статистическая теория регрессионного анализа нечетких переменных строится как частный случай аналогичной теории для переменных произвольной природы (глава 2.2.3). В частности, при обычных предположениях оценки α*, β* являются состоятельными, т.е. α* → α0 и β* → β0 при n → ∞. Кластер-анализ нечетких переменных. Строить группы сходных между собой нечетких переменных (кластеры) можно многими способами. Опишем два семейства алгоритмов. Пусть на пространстве, в котором лежат результаты наблюдений, т.е. на пространстве нечетких множеств, заданы две меры близости ρ и τ (например, это могут быть введенные выше расстояния d и D). Берется один из результатов наблюдений (нечеткое множество) и вокруг него описывается шар радиуса R, определяемый мерой близости ρ. (Напомним, что шаром с центром в х относительно ρ называется множество всех элементов урассматриваемого пространства таких, что ρ(х, у) < R.) Берутся результаты наблюдений (элементы выборки), попавшие в этот шар, и находится их эмпирическое среднее относительно второй меры близости τ. Оно берется за новый центр, вокруг которого снова описывается шар радиуса R относительно ρ, и процедура повторяется. (Чтобы алгоритм был полностью определен, необходимо сформулировать правило выбора элемента эмпирического среднего в качестве нового центра, если эмпирическое среднее состоит более чем из одного элемента.) Когда центр шара зафиксируется (перестанет меняться), попавшие в этот шар элементы объявляются первым кластером и исключаются из дальнейшего рассмотрения. Алгоритм применяется к совокупности оставшихся результатов наблюдений, выделяет из нее второй кластер и т.д. Всегда ли центр шара остановится? При реальных расчетах в течение многих лет так было всегда. Соответствующая теория была построена в 1977 г. [33]. Было доказано, что описанный выше процесс всегда остановится через конечное число шагов. Причем число шагов до остановки оценивается через максимально возможное число результатов наблюдений в шаре радиуса R относительно ρ. Обширное семейство образуют алгоритмы кластер-анализа типа «Дендрограмма», известные также под названием «агломеративные иерархические алгоритмы средней связи». На первом шагу алгоритма из этого семейства каждый результат наблюдения рассматривается как отдельный кластер. Далее на каждом шагу происходит объединение двух самых близких кластеров. Название «Дендрограмма» объясняется тем, что результат работы алгоритма обычно представляется в виде дерева. Каждая его ветвь соответствует кластеру, появляющемуся на каком-либо шагу работы алгоритма. Слияние ветвей соответствует объединению кластеров, а ствол – заключительному шагу, когда все наблюдения оказываются объединенными в один кластер. Для работы алгоритмов кластер-анализа типа «Дендрограмма» необходимо определить расстояние между кластерами. Естественно использовать ассоциативные средние, которыми, как известно, являются обобщенные средние по Колмогорову всевозможных попарных расстояний между элементами двух рассматриваемых кластеров. Итак, расстояние между кластерами K и L, состоящими из n1 и n2 элементов соответственно, определяется по формуле:
где ρ – некоторое расстояние между нечеткими множествами, F – строго монотонная функция (строго возрастающая или строго убывающая). Соображение теории измерений позволяют ограничить круг возможных алгоритмов типа «Дендрограмма». Естественно принять, что единица измерения расстояния выбрана произвольно. Тогда согласно результатам главы 2.1.3 из всех обобщенных средних по Колмогорову годятся только степенные средние, т.е. F(z) = zλ при λ ≠ 0 или F(z) = lnz. Чтобы получить разбиение на кластеры, надо «разрезать» дерево на определенной высоте, т.е. объединять кластеры лишь до тех пор, пока расстояние между ними меньше заранее выбранной константы. При альтернативном подходе заранее фиксируется число кластеров. Рассматривают и двухкритериальную постановку, когда минимизируют сумму (или максимум) внутрикластерных разбросов и число кластеров. Для решения задачи двухкритериальной минимизации либо один из критериев заменяют на ограничение, либо два критерия «свертывают» в один, либо применяют иные подходы (последовательная оптимизация, построение поверхности Парето и др.). При классификации нечетких множеств полезны многие подходы, рассмотренные в главе 3.2, а именно, все подходы, основанные только на использовании расстояний. Сбор и описание нечетких данных. Разработано большое количество процедур описания нечеткости. Так, согласно Э.Борелю понятие «Куча» описывается с помощью функции распределения – при каждом конкретном хзначение функции принадлежности – это доля людей, считающих совокупность х зерен кучей. Результат подобного опроса может дать и кривую иного вида, например, по поводу понятия «молодой» (слева будут отделены «дети», а справа – «люди зрелого и пожилого возраста»). Нечеткая толерантность может оцениваться с помощью случайных толерантностей (см. выше). Целесообразно попытаться выделить наиболее практически полезные простые формы функций принадлежности. Видимо, наиболее простой является «ступенька» - внутри некоторого интервала функция принадлежности равна 1, а вне этого интервала равна 0. Это – простейший способ «размывания» числа путем замены его интервалом. Нечеткое множество описывается двумя числами – концами интервала. Оценки этих чисел можно получить с помощью экспертов. Статистическая теория подобных нечетких множеств рассмотрена в главе 3.5. Тремя числами a < b < c описывается функция принадлежности типа треугольника. При этом левее а и правее сфункция принадлежности равна 0. В точке b функция принадлежности принимает значение 1. На отрезке [a; b] функция принадлежности линейно растет от 0 до 1, а на отрезке [b;c] – линейно убывает от 1 до 0. Оценки трех чисел a < b < cполучают при опросе экспертов. Следующий по сложности вид функции принадлежности – типа трапеции – описывается четырьмя числами a < b< c < d. Левее a и правее d функция принадлежности равна 0. На отрезке [a; b] она линейно возрастает от 0 до 1, на отрезке [b; c] во всех точках равна 1, а на отрезке [c; d] линейно убывает от 1 до 0. Для оценивания четверки чисел a <b < c < d используют экспертов. Ряд результатов статистики нечетких данных приведен в первой монографии российского автора по нечетким множествам [34] и во многих дальнейших публикациях.
|
||
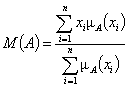 ,
,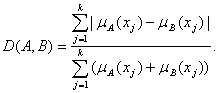
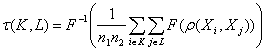 ,
,