«Управление и Оптимизация Производственного Предприятия»
|
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Учебное пособие. Таганрог: Изд-во ТРТУ, 1999 Глава 5. Средние величины. Показатели вариации 5.1. Понятие средней величины Средняя величина – это обобщающий показатель, характеризующий типический уровень явления. Он выражает величину признака, отнесенную к единице совокупности. Средняя всегда обобщает количественную вариацию признака, т.е. в средних величинах погашаются индивидуальные различия единиц совокупности, обусловленные случайными обстоятельствами. В отличие от средней абсолютная величина, характеризующая уровень признака отдельной единицы совокупности, не позволяет сравнивать значения признака у единиц, относящихся к разным совокупностям. Так, если нужно сопоставить уровни оплаты труда работников на двух предприятиях, то нельзя сравнивать по данному признаку двух работников разных предприятий. Оплата труда выбранных для сравнения работников может быть не типичной для этих предприятий. Если же сравнивать размеры фондов оплаты труда на рассматриваемых предприятиях, то не учитывается численность работающих и, следовательно, нельзя определить, где уровень оплаты труда выше. В конечном итоге сравнить можно лишь средние показатели, т.е. сколько в среднем получает один работник на каждом предприятии. Таким образом, возникает необходимость расчета средней величины как обобщающей характеристики совокупности. Вычисление среднего – один из распространенных приемов обобщения; средний показатель отрицает то общее, что характерно (типично) для всех единиц изучаемой совокупности, в то же время он игнорирует различия отдельных единиц. В каждом явлении и его развитии имеет место сочетание случайности и необходимости. При исчислении средних в силу действия закона больших чисел случайности взаимопогашаются, уравновешиваются, поэтому можно абстрагироваться от несущественных особенностей явления, от количественных значений признака в каждом конкретном случае. В способности абстрагироваться от случайности отдельных значений, колебаний и заключена научная ценность средних как обобщающих характеристик совокупностей. Для того, чтобы средний показатель был действительно типизирующим, он должен рассчитываться с учетом определенных принципов. Остановимся на некоторых общих принципах применения средних величин.
5.2. Виды средних и способы их вычисления Рассмотрим теперь виды средних величин, особенности их исчисления и области применения. Средние величины делятся на два больших класса: степенные средние, структурные средние. К степенным средним относятся такие наиболее известные и часто применяемые виды, как средняя геометрическая, средняя арифметическая и средняя квадратическая. В качестве структурных средних рассматриваются мода и медиана. Остановимся на степенных средних. Степенные средние в зависимости от представления исходных данных могут быть простыми и взвешенными. Простая средняя считается по не сгруппированным данным и имеет следующий общий вид:
где Xi – варианта (значение) осредняемого признака;
Взвешенная средняя считается по сгруппированным данным и имеет общий вид
где Xi – варианта (значение) осредняемого признака или серединное значение интервала, в котором измеряется варианта;
Приведем в качестве примера расчет среднего возраста студентов в группе из 20 человек:
Средний возраст рассчитаем по формуле простой средней:
Сгруппируем исходные данные. Получим следующий ряд распределения:
В результате группировки получаем новый показатель – частоту, указывающую число студентов в возрасте Х лет. Следовательно, средний возраст студентов группы будет рассчитываться по формуле взвешенной средней:
Общие формулы расчета степенных средних имеют показатель степени (m). В зависимости от того, какое значение он принимает, различают следующие виды степенных средних:
Формулы степенных средних приведены в табл. 4.4. Если рассчитать все виды средних для одних и тех же исходных данных, то значения их окажутся неодинаковыми. Здесь действует правило мажорантности средних: с увеличением показателя степени m увеличивается и соответствующая средняя величина:
В статистической практике чаще, чем остальные виды средних взвешенных, используются средние арифметические и средние гармонические взвешенные. Таблица 5.1 Виды степенных средних
Средняя гармоническая имеет более сложную конструкцию, чем средняя арифметическая. Среднюю гармоническую применяют для расчетов тогда, когда в качестве весов используются не единицы совокупности – носители признака, а произведения этих единиц на значения признака (т.е. m = Xf). К средней гармонической простой следует прибегать в случаях определения, например, средних затрат труда, времени, материалов на единицу продукции, на одну деталь по двум (трем, четырем и т.д.) предприятиям, рабочим, занятым изготовлением одного и того же вида продукции, одной и той же детали, изделия. Главное требование к формуле расчета среднего значения заключается в том, чтобы все этапы расчета имели реальное содержательное обоснование; полученное среднее значение должно заменить индивидуальные значения признака у каждого объекта без нарушения связи индивидуальных и сводных показателей. Иначе говоря, средняя величина должна исчисляться так, чтобы при замене каждого индивидуального значения осредняемого показателя его средней величиной оставался без изменения некоторый итоговый сводный показатель, связанный тем или другим образом с осредняемым [1] . Этот итоговый показатель называется определяющим, поскольку характер его взаимосвязи с индивидуальными значениями определяет конкретную формулу расчета средней величины. Покажем это правило на примере средней геометрической. Формула средней геометрической
используется чаще всего при расчете среднего значения по индивидуальным относительным величинам динамики. Средняя геометрическая применяется, если задана последовательность цепных относительных величин динамики, указывающих, например, на рост объема производства по сравнению с уровнем предыдущего года: i1, i2, i3,..., in. Очевидно, что объем производства в последнем году определяется начальным его уровнем (q0) и последующим наращиванием по годам: qn=q0× i1× i2×...×in. Приняв qn в качестве определяющего показателя и заменяя индивидуальные значения показателей динамики средними, приходим к соотношению
Отсюда 5.3. Структурные средние Особый вид средних величин – структурные средние – применяется для изучения внутреннего строения рядов распределения значений признака, а также для оценки средней величины (степенного типа), если по имеющимся статистическим данным ее расчет не может быть выполнен (например, если бы в рассмотренном примере отсутствовали данные и об объеме производства, и о сумме затрат по группам предприятий). В качестве структурных средних чаще всего используют показатели моды – наиболее часто повторяющегося значения признака – и медианы – величины признака, которая делит упорядоченную последовательность его значений на две равные по численности части. В итоге у одной половины единиц совокупности значение признака не превышает медианного уровня, а у другой – не меньше его. Если изучаемый признак имеет дискретные значения, то особых сложностей при расчете моды и медианы не бывает. Если же данные о значениях признака Х представлены в виде упорядоченных интервалов его изменения (интервальных рядов), расчет моды и медианы несколько усложняется. Поскольку медианное значение делит всю совокупность на две равные по численности части, оно оказывается в каком-то из интервалов признака X. С помощью интерполяции в этом медианном интервале находят значение медианы:
где XMe – нижняя граница медианного интервала;
В нашем примере могут быть получены даже три медианных значения – исходя из признаков количества предприятий, объема продукции и общей суммы затрат на производство:
Таким образом, у половины предприятий уровень себестоимость единицы продукции превышает 125,19 тыс. руб., половина всего объема продукции производится с уровнем затрат на изделие больше 124,79 тыс. руб. и 50 % общей суммы затрат образуется при уровне себестоимости одного изделия выше 125,07 тыс. руб. Заметим также, что наблюдается некоторая тенденция к росту себестоимости, так как Ме2 = 124,79 тыс. руб., а средний уровень равен 123,15 тыс. руб. При расчете модального значения признака по данным интервального ряда надо обращать внимание на то, чтобы интервалы были одинаковыми, поскольку от этого зависит показатель повторяемости значений признака X. Для интервального ряда с равными интервалами величина моды определяется как
где ХMo – нижнее значение модального интервала;
Для нашего примера можно рассчитать три модальных значения исходя из признаков числа предприятий, объема продукции и суммы затрат. Во всех трех случаях модальный интервал один и тот же, так как для одного и того же интервала оказываются наибольшими и число предприятий, и объем продукции, и общая сумма затрат на производство:
Таким образом, чаще всего встречаются предприятия с уровнем себестоимости 126,75 тыс. руб., чаще всего выпускается продукция с уровнем затрат 126,69 тыс. руб., и чаще всего затраты на производство объясняются уровнем себестоимости в 123,73 тыс. руб. 5.4. Показатели вариации Конкретные условия, в которых находится каждый из изучаемых объектов, а также особенности их собственного развития (социальные, экономические и пр.) выражаются соответствующими числовыми уровнями статистических показателей. Таким образом, вариация, т.е. несовпадение уровней одного и того же показателя у разных объектов, имеет объективный характер и помогает познать сущность изучаемого явления. Для измерения вариации в статистике применяют несколько способов. Наиболее простым является расчет показателя размаха вариации Н как разницы между максимальным (Xmax ) и минимальным (Xmin) наблюдаемыми значениями признака: H=Xmax - Xmin. Однако размах вариации показывает лишь крайние значения признака. Повторяемость промежуточных значений здесь не учитывается. Более строгими характеристиками являются показатели колеблемости относительно среднего уровня признака. Простейший показатель такого типа – среднее линейное отклонение Л как среднее арифметическое значение абсолютных отклонений признака от его среднего уровня:
При повторяемости отдельных значений Х используют формулу средней арифметической взвешенной:
(Напомним, что алгебраическая сумма отклонений от среднего уровня равна нулю.) Показатель среднего линейного отклонения нашел широкое применение на практике. С его помощью анализируются, например, состав работающих, ритмичность производства, равномерность поставок материалов, разрабатываются системы материального стимулирования. Но, к сожалению, этот показатель усложняет расчеты вероятностного типа, затрудняет применение методов математической статистики. Поэтому в статистических научных исследованиях для измерения вариации чаще всего применяют показатель дисперсии. Дисперсия признака (s2) определяется на основе квадратической степенной средней:
Показатель s, равный В общей теории статистики показатель дисперсии является оценкой одноименного показателя теории вероятностей и (как сумма квадратов отклонений) оценкой дисперсии в математической статистике, что позволяет использовать положения этих теоретических дисциплин для анализа социально-экономических процессов. Если вариация оценивается по небольшому числу наблюдений, взятых из неограниченной генеральной совокупности, то и среднее значение признака определяется с некоторой погрешностью. Расчетная величина дисперсии оказывается смещенной в сторону уменьшения. Для получения несмещенной оценки выборочную дисперсию, полученную по приведенным ранее формулам, надо умножить на величину n / (n - 1). В итоге при малом числе наблюдений (< 30) дисперсию признака рекомендуется вычислять по формуле
Обычно уже при n > (15÷20) расхождение смещенной и несмещенной оценок становится несущественным. По этой же причине обычно не учитывают смещенность и в формуле сложения дисперсий. Если из генеральной совокупности сделать несколько выборок и каждый раз при этом определять среднее значение признака, то возникает задача оценки колеблемости средних. Оценить дисперсию среднего значения можно и на основе всего одного выборочного наблюдения по формуле
где n – объем выборки; s2 – дисперсия признака, рассчитанная по данным выборки. Величина Показатели относительного рассеивания. Для характеристики меры колеблемости изучаемого признака исчисляются показатели колеблемости в относительных величинах. Они позволяют сравнивать характер рассеивания в различных распределениях (различные единицы наблюдения одного и того же признака в двух совокупностях, при различных значениях средних, при сравнении разноименных совокупностей). Расчет показателей меры относительного рассеивания осуществляют как отношение абсолютного показателя рассеивания к средней арифметической, умножаемое на 100%. 1. Коэффициентом осцилляции отражает относительную колеблемость крайних значений признака вокруг средней
2. Относительное линейное отключение характеризует долю усредненного значения признака абсолютных отклонений от средней величины
3. Коэффициент вариации:
является наиболее распространенным показателем колеблемости, используемым для оценки типичности средних величин. В статистике совокупности, имеющие коэффициент вариации больше 30–35 %, принято считать неоднородными. У такого способа оценки вариации есть и существенный недостаток. Действительно, пусть, например, исходная совокупность рабочих, имеющих средний стаж 15 лет, со средним квадратическим отклонением s = 10 лет, «состарилась» еще на 15 лет. Теперь
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||
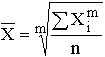 ,
,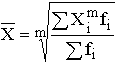 ,
,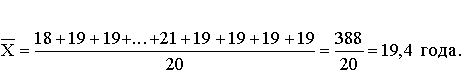
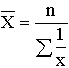
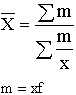
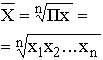
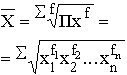
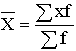
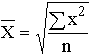
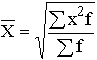
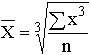
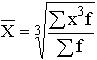
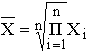
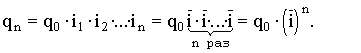
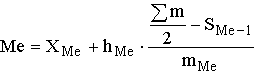 ,
,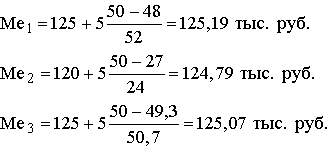
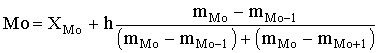 ,
,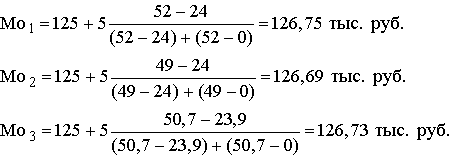
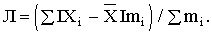
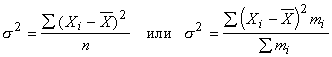 .
.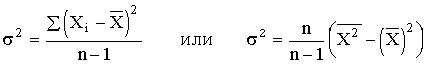 .
.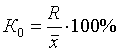 .
.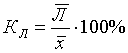 .
.