«Управление и Оптимизация Производственного Предприятия»
|
|
|
|
|
Под общей редакцией академика РАЕН, д.э.н. Г.Б. Клейнера Москва, «КОНСЭКО»,1998 Приложение 1. Методы статистического анализа и прогнозирования в бизнесе 2. Математические модели как необходимый инструмент статистического анализа и прогнозирования в бизнесе Начнем с простого примера демонстрирующего различия чисто статистического, чисто вероятностного ивероятностно-статистического подходов к выработке прогнозного решения. Одновременно на этом примере достаточно прозрачно видна роль математических моделей в технологии формирования прогнозного решения. Статистический способ принятия решения. Пусть читатель представит себя бизнесменом, наблюдающим за игрой двух его приятелей-бизнесменов (А и В) в кости. Игра идет по следующим правилам. Производится четыре последовательных бросания игральной кости. Игрок А получает одну денежную единицу от игрока В, если в результате этих четырех бросаний хотя бы один раз выпало шесть очков (назовем этот исход «шесть»), и платит одну денежную единицу игроку В в противном случае (назовем этот исход «не шесть»). После ста туров читатель должен сменить одного из игроков, причем он имеет право выбрать ситуацию, на которую он будет ставить свою денежную единицу в следующей серии туров: за появление хотя бы одной «шестерки» или против. Правильное осуществление этого выбора определяется, естественно, качеством его прогноза по поводу результата игры при ставке на исход «шесть»: если вероятность этого исхода правильно оценивается величиной, превосходящей половину, то игрок должен поставить именно на этот исход. Итак, задача наблюдателя – сделать достоверный прогноз. Статистический способ решения этой задачи диктуется обычным здравым смыслом и заключается в следующем. Пронаблюдав сто туров игры предыдущих партнеров и подсчитав относительные частоты их выигрыша, казалось бы, естественно поставить на ту ситуацию, которая чаще возникала в процессе игры. Например, было зафиксировано, что в 52 партиях из 100 выиграл игрок В, т.е. в 52 турах из 100 «шестерка» не выпадала ни разу при четырехкратном выбрасывании кости (соответственно в остальных 48 партиях из ста осуществлялся исход «шесть»). Следовательно, делает вывод читатель, применивший статистический способ рассуждения, выгоднее ставить на исход «не шесть», т.е. на тот исход, относительная частота появления которого Теоретико-вероятностный способ решения. Этот способ основан на определенной математической моделиизучаемого явления: полагая кость правильной (т. е. симметричной), а следовательно, принимая шансы выпадения любой грани кости при одном бросании равными между собой (другими словами, относительная частота, или вероятность, выпадения «единицы» равна относительной частоте выпадения «двойки», «тройки» и т. д. и равна 1/6), можно подсчитать вероятность P {«не шесть»} осуществления ситуации «не шесть», т. е. вероятность события, заключающегося в том, что при четырех последовательных бросаниях игральной кости ни разу не появится «шестерка». Этот расчет основан на следующих фактах, вытекающих из принятых нами предпосылок модели. Вероятность не выбросить шестерку при одном бросании кости складывается из шансов появиться в результате одного бросания «единице», «двойке», «тройке», «четверке»и «пятерке» и, следовательно, составляет (в соответствии с определением вероятности любого события) величину 5/6. Затем используем правило умножения вероятностей, в соответствии с которым вероятность наступления нескольких независимых событий равна произведению вероятностей этих событий. В нашем случае мы рассматриваем факт наступления четырех независимых событий, каждое из которых заключается в невыпадении «шестерки» при одном бросании и имеет вероятность осуществления, равную 5/6. Поэтому
Как видно, вероятность ситуации «не шесть» оказалась меньше половины, следовательно, шансы ситуации «шесть» предпочтительнее (соответствующая вероятность равна: 1-0,482 = 0,518). А значит, читатель, использовавший теоретико-вероятностный способ рассуждения, придет к диаметрально противоположному по сравнению с читателем со статистическим образом мышления решению и будет ставить в игре на ситуацию «шесть». Вероятностно-статистический (или математико-статистический) способ принятия решения. Этот способ как бы синтезирует инструментарий двух предыдущих, так как при выработке с его помощью окончательного вывода используются и накопленные в результате наблюдения за игрой исходные статистические данные (в виде относительных частот появления ситуаций «шесть» и «не шесть», которые, как мы помним, были равны соответственно 0,48 и 0,52), и теоретико-вероятностные модельные соображения. Однако модель, принимаемая в данном случае, менее жестка, менее ограничена, она как бы настраивается на реальную действительность, используя для этого накопленную статистическую информацию. В частности, эта модель уже не постулирует правильность используемых костей, допуская, что центр тяжести игральной кости может быть и смещен некоторым особым образом. Характер этого смещения (если оно есть) должен как-то проявиться в тех исходных статистических данных, которыми мы располагаем. Однако читатель, владеющий вероятностно-статистическим образом мышления, должен отдавать себе отчет в том, что полученные из этих данных величины относительных частот исходов «шесть» и «не шесть» дают лишь некоторые приближенные оценки истинных (теоретических) шансов той и другой ситуации: ведь подбрасывая, скажем, 10 раз даже идеально симметричную монету, мы можем случайно получить семь выпадений «гербов»; соответственно относительная частота выпадения «герба», подсчитанная по этим результатам испытаний, будет равна 0,7; но это еще не значит, что истинные (теоретические) шансы (вероятности) появления «герба» и другой стороны монеты оцениваются величинами соответственно 0,7 и 0,3, – эти вероятности, как мы знаем, равны 0,5. Точно так же установленная нами в серии из ста игровых туров относительная частота исхода «не шесть» (равная 0,52) может отличаться от истинной (теоретической) вероятности того же события и, значит, может не быть достаточным основанием для выбора этой ситуации в игре! Получается, что весь вопрос заключается в том, насколько сильно может отличаться наблюденная (в результате осуществления n испытаний) относительная частота Эти соображения, в частности, позволяют оценить абсолютную величину погрешности Приближенный подсчет максимально возможной величины этой погрешности, опирающийся на модельное соображение б) (т. е. теорему Муавра-Лапласа, см. [1] и п. 4.3), дает в рассматриваемом примере, что с практической достоверностью, а именно с вероятностью 0,95, справедливо неравенство
Возведение этого неравенства в квадрат и решение получившегося квадратного неравенства относительно неизвестного параметра
или, с точностью до величин порядка малости выше, чем В данном случае (при
Следовательно,
Таким образом, наблюдения за исходами ста партий дают нам основания лишь заключить, что интересующая нас неизвестная величина вероятности исхода «не шесть» на самом деле может быть любым числом из отрезка [0,42; 0,62], т. е. может быть как величиной, меньшей 0,5 (и тогда надо ставить в игре на ситуацию «шесть»), так и величиной, большей 0,5 (и тогда надо ставить в игре на ситуацию «не шесть»). Иначе говоря, читатель, воспользовавшийся вероятностно-статистическим способом решения задачи и указанными выше модельными предпосылками, должен прийти к следующему «осторожному» выводу: ста партий в качестве исходного статистического материала оказалось недостаточно для вынесения надежного заключения о том, какой из исходов игры является более вероятным. Отсюда решение: либо продолжить роль «зрителя» до тех пор, пока область возможных значений для вероятности Приведенный пример иллюстрирует роль и назначение теоретико-вероятностных и математико-статистических методов, их взаимоотношения. Если теория вероятностей предоставляет исследователю набор математических моделей, предназначенных для описания закономерностей в поведении реальных явлений или систем, функционирование которых происходит под влиянием большого числа взаимодействующих случайных факторов, то средства математической статистики позволяют подбирать среди множества возможных теоретико-вероятностных моделей ту, которая в определенном смысле наилучшим образом соответствует имеющимся в распоряжении исследователя статистическим данным, характеризующим реальное поведение конкретной исследуемой системы. Математическая модель. Математическая модель – это некоторая математическая конструкция, представляющая собой абстракцию реального мира: в модели интересующие исследователя отношения между реальными элементами заменены подходящими отношениями между элементами математической конструкции (математическими категориями). Эти отношения, как правило, представлены в форме уравнений и (или) неравенств между показателями (переменными), характеризующими функционирование моделируемой реальной системы. Искусство построения математической модели состоит в том, чтобы совместить как можно большую лаконичность в ее математическом описании с достаточной точностью модельного воспроизводства именно тех сторон анализируемой реальности, которые интересуют исследователя. Выше, анализируя взаимоотношения чисто статистического, чисто теоретико-вероятностного и смешанного – вероятностно-статистического способа рассуждения, мы, в действительности, пользовались простейшими моделями, а именно: статистической частотной моделью интересующего нас случайного события, заключающегося в том, что в результате четырех последовательных бросаний игральной кости ни разу не выпадет «шестерка»; оценив по предыстории относительную частоту теоретико-вероятностной моделью последовательности испытаний Бернулли (см. [1] и п. 3.1.1), которая никак не связана с использованием результатов наблюдений (т. е. со статистикой); для подсчета вероятности интересующего нас события достаточно принятия гипотетического допущения о том, что используемая игральная кость идеально симметрична. Тогда в соответствии с моделью серии независимых испытаний и справедливой, в рамках этой модели, теоремой умножения вероятностей подсчитывается интересующая нас вероятность по формуле вероятностно-статистической моделью, интерпретирующей оцененную в чисто статистическом подходе относительную частоту Обобщая этот пример, можно сказать, что: вероятностная модель – это математическая модель, имитирующая механизм функционирования гипотетического(не конкретного) реального явления (или системы) стохастической природы; в нашем примере гипотетичность относилась к свойствам игральной кости: она должна была быть идеально симметричной; вероятностно-статистическая модель – это вероятностная модель, значения отдельных характеристик (параметров) которой оцениваются по результатам наблюдений (исходным статистическим данным), характеризующим функционирование моделируемого конкретного (а не гипотетического) явления (или системы). Вероятностно-статистическая модель, описывающая механизм функционирования экономической или социально-экономической системы, называется эконометрической. Прогностические и управленческие модели в бизнесе. Вернемся к задачам статистического анализа механизма функционирования предприятия (фирмы) и связанным с ними прогнозами. Вновь рассматривая «фазовое пространство» этих задач, нетрудно описать общую логическую структуру необходимых для их решения моделей. Эта структура прямо следует из сформулированного выше определения стратегии бизнеса. Для того чтобы формализовать (т. е. записать в терминах математической модели) задачи оптимального управления и построения прогноза в бизнесе, введем следующие обозначения:
Тогда система уравнений, на базе которых может осуществляться оптимальное управление предприятием ивыполнение необходимых прогнозных расчетов, в самом общем виде может быть представлена в форме: где Тогда базовая проблема статистического анализа и прогнозирования в бизнесе состоит в построении наилучшей (в определенном смысле) оценки где В (7) и (8) имеется в виду покомпонентное выполнение соответствующих векторно-значных неравенств. Если базовая проблема статистического анализа и прогнозирования решена, то решения задач оптимального управления и прогноза могут быть описаны следующим образом. Задача оптимального управления. Пусть где под Задача прогнозирования результирующих показателей. Пусть где величина приращения Некоторые общие сведения о математическом инструментарии решения задач (9) и (10) см. ниже, в п. 4. |
||
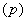 равна 0,52 (больше половины).
равна 0,52 (больше половины).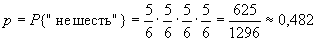
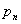 интересующего нас события от истинной вероятности
интересующего нас события от истинной вероятности 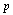 появления этого события, и как это отличие, т. е. погрешность
появления этого события, и как это отличие, т. е. погрешность 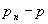 , зависит от числа
, зависит от числа 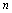 имеющихся в нашем распоряжении наблюдений (интуитивно ясно, что чем дольше мы наблюдали за игрой, т. е. чем больше общее число
имеющихся в нашем распоряжении наблюдений (интуитивно ясно, что чем дольше мы наблюдали за игрой, т. е. чем больше общее число 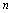 использованных нами наблюдений, тем больше доверия заслуживают вычисленные нами эмпирические относительные частоты
использованных нами наблюдений, тем больше доверия заслуживают вычисленные нами эмпирические относительные частоты 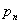 , т. е. тем меньше их отличие от неизвестных нам истинных значений вероятностей
, т. е. тем меньше их отличие от неизвестных нам истинных значений вероятностей 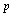 ). Ответ на этот вопрос можно получить в нашем случае, если воспользоваться рядом дополнительных модельных соображений: а) предположить, что результат каждого тура никак не зависит от результатов предыдущих туров, а неизвестная нам вероятность
). Ответ на этот вопрос можно получить в нашем случае, если воспользоваться рядом дополнительных модельных соображений: а) предположить, что результат каждого тура никак не зависит от результатов предыдущих туров, а неизвестная нам вероятность 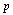 осуществления ситуации «не шесть» остается одной и той же на протяжении всех туров игры; б) использовать тот факт, что поведение случайно меняющейся (при повторениях эксперимента) погрешности
осуществления ситуации «не шесть» остается одной и той же на протяжении всех туров игры; б) использовать тот факт, что поведение случайно меняющейся (при повторениях эксперимента) погрешности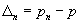 приближенно описывается законом нормального распределения вероятностей со средним значением, равным нулю, и дисперсией, равной
приближенно описывается законом нормального распределения вероятностей со средним значением, равным нулю, и дисперсией, равной 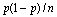 (см. [1], п. 3.1.5).
(см. [1], п. 3.1.5).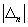 , заменяя неизвестную величину
, заменяя неизвестную величину  вероятности интересующего нас события (в нашем случае – исход «не шесть») относительной частотой
вероятности интересующего нас события (в нашем случае – исход «не шесть») относительной частотой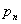 этого события, зафиксированной в серии из
этого события, зафиксированной в серии из  испытаний (в нашем случае
испытаний (в нашем случае 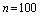 , а
, а 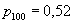 ). Если же мы смогли численно оценить абсолютную величину возможной погрешности
). Если же мы смогли численно оценить абсолютную величину возможной погрешности 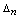 , то естественно применить следующее правило принятия решения: если относительная частота
, то естественно применить следующее правило принятия решения: если относительная частота 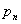 появления исхода «не шесть» больше половины и продолжает превышать 0,5 после вычитания из нее возможной погрешности
появления исхода «не шесть» больше половины и продолжает превышать 0,5 после вычитания из нее возможной погрешности 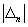 , то выгоднее ставить на «не шесть»; если относительная частота
, то выгоднее ставить на «не шесть»; если относительная частота  меньше половины и продолжает быть меньше 0,5 после прибавления к ней возможной погрешности
меньше половины и продолжает быть меньше 0,5 после прибавления к ней возможной погрешности 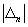 , то выгоднее ставить на «шесть»; в других случаях у наблюдателя нет оснований для статистического вывода о преимуществах того или иного выбора ставки в игре (т. е. надо либо продолжить наблюдения, либо участвовать в игре с произвольным выбором ставки, ожидая, что это не может привести к сколько-нибудь ощутимому выигрышу или проигрышу).
, то выгоднее ставить на «шесть»; в других случаях у наблюдателя нет оснований для статистического вывода о преимуществах того или иного выбора ставки в игре (т. е. надо либо продолжить наблюдения, либо участвовать в игре с произвольным выбором ставки, ожидая, что это не может привести к сколько-нибудь ощутимому выигрышу или проигрышу).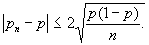
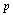 дает
дает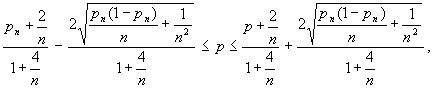
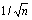 ,
, (4)
(4)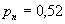 и
и 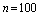 ) получаем:
) получаем: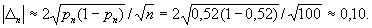
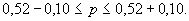
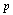 , полученная из оценок вида (4), не окажется целиком лежащей левее или правее 0,5, либо вступить в игру, оценивая ее как близкую к «безобидной», т. е. к такой, в которой в длинной серии туров практически останешься «при своих».
, полученная из оценок вида (4), не окажется целиком лежащей левее или правее 0,5, либо вступить в игру, оценивая ее как близкую к «безобидной», т. е. к такой, в которой в длинной серии туров практически останешься «при своих».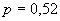 этого события и приняв ее за вероятность появления этого события в будущем ряду испытаний, мы, тем самым, используем модель случайного эксперимента с известной вероятностью его исхода (см. [1] и п. 1.1.3);
этого события и приняв ее за вероятность появления этого события в будущем ряду испытаний, мы, тем самым, используем модель случайного эксперимента с известной вероятностью его исхода (см. [1] и п. 1.1.3);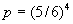 ;
;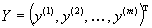 – вектор-столбец результирующих показателей (объем продаж и т. п.);
– вектор-столбец результирующих показателей (объем продаж и т. п.);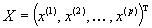 – вектор-столбец «поведенческих» (управляемых) переменных (вложения в развитие основных фондов, в службы маркетинга и т. п.);
– вектор-столбец «поведенческих» (управляемых) переменных (вложения в развитие основных фондов, в службы маркетинга и т. п.);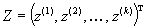 – вектор-столбец так называемых «статусных» переменных, т. е. показателей, характеризующих состояние фирмы (число работников, основные фонды, возраст фирмы и т. п.);
– вектор-столбец так называемых «статусных» переменных, т. е. показателей, характеризующих состояние фирмы (число работников, основные фонды, возраст фирмы и т. п.);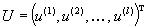 – вектор-столбец гео-социо-экономико-демографичес-ких характеристик внешней среды (показатели общей экономической ситуации, характеристики клиентов и поставщиков и т. п.);
– вектор-столбец гео-социо-экономико-демографичес-ких характеристик внешней среды (показатели общей экономической ситуации, характеристики клиентов и поставщиков и т. п.);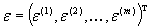 – вектор-столбец случайных регрессионных остатков (подробнее о них ниже).
– вектор-столбец случайных регрессионных остатков (подробнее о них ниже).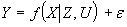 , (5)
, (5)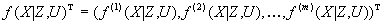 – некоторая векторнозначная (
– некоторая векторнозначная ( 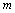 -мерная) функция от
-мерная) функция от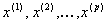 , структура (значения параметров) которой, вообще говоря, зависит от того, на каких уровнях зафиксированы величины переменных «состояния» фирмы
, структура (значения параметров) которой, вообще говоря, зависит от того, на каких уровнях зафиксированы величины переменных «состояния» фирмы 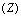 и «внешней среды»
и «внешней среды» 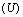 .
.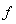
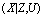 для неизвестной функции
для неизвестной функции 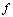
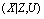 по имеющейся в распоряжении исследователя исходной статистической информации вида
по имеющейся в распоряжении исследователя исходной статистической информации вида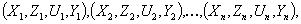 (6)
(6) – значения соответственно поведенческих, «статусных», внешних и результирующих переменных, характеризующие
– значения соответственно поведенческих, «статусных», внешних и результирующих переменных, характеризующие  -й такт времени (или измеренных на
-й такт времени (или измеренных на 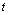 -м статистически обследованном предприятии),
-м статистически обследованном предприятии), 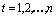 . Соответственно параметр
. Соответственно параметр 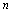 (объем выборки) интерпретируется как общая длительность наблюдений за значениями анализируемых переменных на исследуемом предприятии, если наблюдения регистрировались во времени, и как общее число статистически обследованных однотипных предприятий, если наблюдения регистрировались в пространстве(т. е., переходя от одного предприятия к другому). При этом описание функции
(объем выборки) интерпретируется как общая длительность наблюдений за значениями анализируемых переменных на исследуемом предприятии, если наблюдения регистрировались во времени, и как общее число статистически обследованных однотипных предприятий, если наблюдения регистрировались в пространстве(т. е., переходя от одного предприятия к другому). При этом описание функции 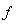
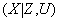 должно сопровождаться способом расчета гарантированных погрешностей аппроксимации (ошибок прогноза), т. е. таких векторных (
должно сопровождаться способом расчета гарантированных погрешностей аппроксимации (ошибок прогноза), т. е. таких векторных ( 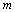 -мерных) значений
-мерных) значений 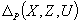 и
и 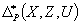 , которые для любых заданных значений
, которые для любых заданных значений 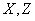 и
и 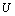 гарантировали бы выполнение неравенств (с вероятностью, не меньшей, чем
гарантировали бы выполнение неравенств (с вероятностью, не меньшей, чем  , где
, где 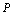 – наперед заданная, достаточно близкая к единице положительная величина)
– наперед заданная, достаточно близкая к единице положительная величина)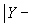
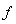
 (7)
(7)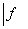
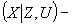
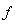
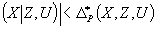 . (8)
. (8)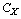 – некоторое подмножество в фазовом подпространстве поведенческих переменных
– некоторое подмножество в фазовом подпространстве поведенческих переменных 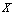 , с помощью которого определяются ресурсные и другие ограничения на возможные значения
, с помощью которого определяются ресурсные и другие ограничения на возможные значения  , т.е.
, т.е. . Тогда оптимальные значения
. Тогда оптимальные значения  поведенческих (управляемых) переменных
поведенческих (управляемых) переменных 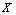 определяются как решение оптимизационной задачи вида
определяются как решение оптимизационной задачи вида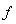
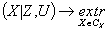 , (9)
, (9)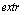 понимаются минимальные или максимальные значения компонент функции
понимаются минимальные или максимальные значения компонент функции  (в зависимости от их содержательного смысла).
(в зависимости от их содержательного смысла).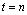 – текущий момент времени (им заканчиваетсябазовый, т.е. статистически обследованный интервал времени [1; n]). И пусть заданы (нормативные, спрогнозированные) значения
– текущий момент времени (им заканчиваетсябазовый, т.е. статистически обследованный интервал времени [1; n]). И пусть заданы (нормативные, спрогнозированные) значения 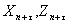 и
и 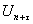 соответственно поведенческих (управляемых), «статусных» и переменных внешней среды для момента времени
соответственно поведенческих (управляемых), «статусных» и переменных внешней среды для момента времени 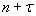 (
(  – горизонт прогнозирования, измеряется в целом числе принятых в исследовании временных тактов). Тогда общая структура прогноза
– горизонт прогнозирования, измеряется в целом числе принятых в исследовании временных тактов). Тогда общая структура прогноза  значений результирующих показателей
значений результирующих показателей 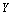 на
на 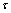 временных тактов вперед имеет вид:
временных тактов вперед имеет вид: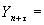
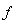
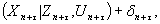 (10)
(10)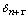 , как правило, достаточно мала по сравнению с
, как правило, достаточно мала по сравнению с 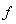
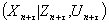 и зависит от вероятностной природы регрессионных остатков
и зависит от вероятностной природы регрессионных остатков 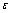 в соотношении (5) (например, в рамках допущений, принятых вклассической модели регрессии, величина
в соотношении (5) (например, в рамках допущений, принятых вклассической модели регрессии, величина 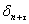 тождественно равна нулю (см [1, гл. 15]).
тождественно равна нулю (см [1, гл. 15]).