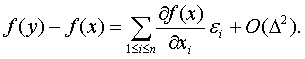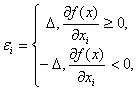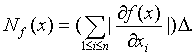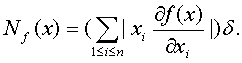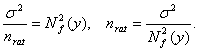«Управление и Оптимизация Производственного Предприятия»
|
|
|
|
|
Теория принятия решений Учебное пособие. - М.: Издательство "Март", 2004. 2. ОПИСАНИЕ НЕОПРЕДЕЛЕННОСТЕЙ В ТЕОРИИ ПРИНЯТИЯ РЕШЕНИЙ 2.3.2. Основные идеи асимптотической математической статистики интервальных данныхПусть существо реального явления описывается выборкой x1 , x2 , ..., xn . В вероятностной теории математической статистики, из которой мы исходим (см. терминологическую статью [24]), выборка - это набор независимых в совокупности одинаково распределенных случайных величин. Однако беспристрастный и тщательный анализ подавляющего большинства реальных задач показывает, что статистику известна отнюдь не выборка x1 , x2 , ..., xn , а величины yj = xj + где Одна из причин появления погрешностей - запись результатов наблюдений с конечным числом значащих цифр. Дело в том, что для случайных величин с непрерывными функциями распределения событие, состоящее в попадании хотя бы одного элемента выборки в множество рациональных чисел, согласно правилам теории вероятностей имеет вероятность 0, а такими событиями в теории вероятностей принято пренебрегать. Поэтому при рассуждениях о выборках из нормального, логарифмически нормального, экспоненциального, равномерного, гамма - распределений, распределения Вейбулла-Гнеденко и др. приходится принимать, что эти распределения имеют элементы исходной выборки x1 , x2 , ...,xn, в то время как статистической обработке доступны лишь искаженные значения yj = xj + Введем обозначения x = (x1 , x2 , ..., xn ), y = (y1 , y2 , ..., yn ), Пусть статистические выводы основываются на статистике Очевидно, в статистических выводах необходимо отразить различие между f(y) и f(x). Одним из двух основных понятий статистики интервальных данных является понятие нотны. Определение. Величину максимально возможного (по абсолютной величине) отклонения, вызванного погрешностями наблюдений Nf(x) = sup | f(y) - f(x) | , где супремум берется по множеству возможных значений вектора погрешностей Если функция f имеет частные производные второго порядка, а ограничения на погрешности имеют вид
причем
Чтобы получить асимптотическое (при
а минимум, отличающийся от максимума только знаком, достигается при порядка имеет вид
Это выражение назовем асимптотической нотной. Условие (1) означает, что исходные данные представляются статистику в виде интервалов Если задана не предельная абсолютная погрешность
то аналогичным образом получаем, что нотна с точностью до бесконечно малых более высокого порядка, т.е. асимптотическая нотна, имеет вид
При практическом использовании рассматриваемой концепции необходимо провести тотальную замену символов x на символы y. В каждом конкретном случае удается показать, что в силу малости погрешностей разность Основные результаты в вероятностной модели. В классической вероятностной модели элементы исходной выборки x1, x , ..., xn рассматриваются как независимые одинаково распределенные случайные величины. Как правило, существует некоторая константа C > 0 такая, что в смысле сходимости по вероятности
Соотношение (2) доказывается отдельно для каждой конкретной задачи. При использовании классических эконометрических методов в большинстве случаев используемая статистика f(x)является асимптотически нормальной. Это означает, что существуют константы а и
где
и
а потому в классической эконометрике средний квадрат ошибки статистической оценки равен
с точностью до членов более высокого порядка. В статистике интервальных данных ситуация совсем иная - обычно можно доказать, что средний квадрат ошибки равен
Из соотношения (3) можно сделать ряд важных следствий. Прежде всего отметим, что правая часть этого равенства, в отличие от правой части соответствующего классического равенства, не стремится к 0 при безграничном возрастании объема выборки. Она остается больше некоторого положительного числа, а именно, квадрата нотны. Следовательно, статистика f(x) не является состоятельной оценкой параметра a. Более того, состоятельных оценок вообще не существует. Пусть доверительным интервалом для параметра a, соответствующим заданной доверительной вероятности В статистике интервальных данных методы оценивания параметров имеют другие свойства по сравнению с классической математической статистикой. Так, при больших объемах выборок метод моментов может быть заметно лучше, чем метод максимального правдоподобия (т.е. иметь меньший средний квадрат ошибки - см. формулу (3)), в то время как в классической математической статистике второй из названных методов всегда не хуже первого. Рациональный объем выборки. Анализ формулы (3) показывает, что в отличие от классической математической статистики нецелесообразно безгранично увеличивать объем выборки, поскольку средний квадрат ошибки остается всегда большим квадрата нотны. Поэтому представляется полезным ввести понятие "рационального объема выборки"nrat, при достижении которого продолжать наблюдения нецелесообразно. Как установить "рациональный объем выборки"? Можно воспользоваться идеей "принципа уравнивания погрешностей", выдвинутой в монографии [3]. Речь идет о том, что вклад погрешностей различной природы в общую погрешность должен быть примерно одинаков. Этот принцип дает возможность выбирать необходимую точность оценивания тех или иных характеристик в тех случаях, когда это зависит от исследователя. В статистике интервальных данных в соответствии с "принципом уравнивания погрешностей" предлагается определять рациональный объем выборки nrat из условия равенства двух величин - метрологической составляющей, связанной с нотной, и статистической составляющей - в среднем квадрате ошибки (3), т.е. из условия
Для практического использования выражения для рационального объема выборки неизвестные теоретические характеристики необходимо заменить их оценками. Это делается в каждой конкретной задаче по-своему. Исследовательскую программу в области статистики интервальных данных можно "в двух словах" сформулировать так: для любого алгоритма анализа данных (алгоритма прикладной статистики) необходимо вычислить нотну и рациональный объем выборки. Или иные величины из того же понятийного ряда, возникающие в многомерном случае, при наличии нескольких выборок и при иных обобщениях описываемой здесь простейшей схемы. Затем проследить влияние погрешностей исходных данных на точность оценивания, доверительные интервалы, значения статистик критериев при проверке гипотез, уровни значимости и другие характеристики статистических выводов. Очевидно, классическая математическая статистика является частью статистики интервальных данных, выделяемой условием
|
||