«Управление и Оптимизация Производственного Предприятия»
|
|
|
|
|
М.: МЗ-Пресс, 2004. Глава 2. Статистические методы в пространствах произвольной природы 2.7. Методы восстановления зависимостей Сначала рассмотрим параметрические постановки задач регрессионного анализа (восстановления зависимостей) в пространствах произвольной природы, затем - непараметрические, после чего перейдем к оцениванию нечисловых параметров в классической ситуации, когда отклик и факторы принимают числовые значения. Задача аппроксимации зависимости (параметрической регрессии). Пусть X и Y – некоторые пространства. Пусть имеются статистические данные - n пар (xk, yk), где xk
Часто, но не всегда, все fk совпадают. В классической постановке, когда Х = Rk, У = R1, функции fk различны при неравноточных наблюдениях, например, когда число опытов меняется от одной точки х проведения опытов к другой. Если fk(y1,y2) = f(y1,y2) = (y1 - y2)2, то получаем общую постановку метода наименьших квадратов (см. подробности, например, в [6, гл.5]):
В рамках детерминированного анализа данных остается единственный теоретический вопрос – о существовании θn. Если все участвующие в формулировке задачи (1) функции непрерывны, а минимум берется по бикомпакту, то θnсуществует. Есть и иные условия существования θn [4, 36, 37]. При появлении нового наблюдения х в соответствии с методологией восстановления зависимости рекомендуется выбирать оценку соответствующего у по правилу у* = g(x, θn). Обосновать такую рекомендацию в рамках детерминированного анализа данных невозможно. Это можно сделать только в вероятностной теории, равно как и изучить асимптотическое поведение θn, доказать состоятельность этой оценки. Как и в классическом случае, вероятностную теорию целесообразно строить для трех различных постановок. 1. Переменная х – детерминированная (например, время), переменная у – случайная, ее распределение зависит отх. 2. Совокупность (xk, yk), k = 1, 2, …, n, – выборка из распределения случайного элемента со значениями в ХЧУ. 3. Имеется детерминированный набор пар (xk0, yk0), k = 1, 2, …, n, результат наблюдения (xk, yk) является случайным элементом, распределение которого зависит от (xk0, yk0). Это – постановка т.н. конфлюэнтного анализа. Во всех трех случаях
однако случайность входит в правую часть по-разному в зависимости от постановки, от которой зависит и определение предельной функции f(θ). Проще всего выглядит f(θ) в случае второй постановки при fk ≡ f: f(θ) = Mf(g(x1,θ),y). В случае первой постановки
в предположении существования указанного предела. Ситуация усложняется для третьей постановки:
Во всех трех случаях на основе общих результатов о поведении решений экстремальных статистических задач можно изучить [4, 36, 37] асимптотику оценок θn. При выполнении соответствующих внутриматематических условий регулярности оценки оказываются состоятельными, т.е. удается восстановить зависимость. Аппроксимация и регрессия. Соотношение (1) дает решение задачи аппроксимации. Поясним, как эта задача соотносится с нахождением регрессии. Согласно [38] для случайной величины (ξ, η) со значениями в ХЧУ регрессией η на ξ относительно меры близости f естественно назвать решение задачи Mf(g(ξ), η) → где f: YЧY → R1, g: X → Y, минимум берется по множеству всех измеримых функций. Можно исходить и из формально другого определения. Для каждого х
Оказывается, при обычных предположениях измеримости решение задачи (2) совпадает с Если заранее известно, что условное математическое ожидание Если же нет оснований считать, что регрессия принадлежит некоторому параметрическому семейству, то можно использовать непараметрические оценки регрессии. Они строятся с помощью непараметрических оценок плотности (см. раздел 2.5). Непараметрические методы восстановления зависимости. Пусть ν1 – мера в Х, ν2 – мера в У, а их прямое произведение ν = ν1Чν2 – мера в ХЧУ. Пусть g(x,y) – плотность случайного элемента (ξ,η) по мере ν. Тогда условная плотность g(y|x) распределения η при условии ξ=х имеет вид
(в предположении, что интеграл в знаменателе отличен от 0). Следовательно,
а потому
Заменяя g(x,y) в (3) непараметрической оценкой плотности gn(x,y), получаем оценку условной плотности
Если gn(x,y) – состоятельная оценка g(x,y), то числитель (4) сходится к числителю (3). Сходимость знаменателя (4) к знаменателю (3) обосновывается с помощью предельной теории статистик интегрального типа (см. раздел 2.6). В итоге получаем утверждение о состоятельности непараметрической оценки (4) условной плотности (3). Непараметрическая оценка регрессии ищется как
Состоятельность этой оценки следует из приведенных выше общих результатов об асимптотическом поведении решений экстремальных статистических задач. Оценивание объектов нечисловой природы в классических постановках регрессионного анализа.Нечисловая статистика тесно связана с классическими областями прикладной статистики. Ряд трудностей в классических постановках удается понять и разрешить лишь с помощью общих результатов прикладной статистики. В частности, это касается оценивания параметров, когда параметр имеет нечисловую природу. Рассмотрим типовую прикладную постановку задачи восстановления регрессионной зависимости, линейной по параметрам (см. также [6, глава 5.1]). Исходные данные имеют вид
где m - неизвестная степень полинома; Замечание. Здесь наглядно проявляется одна из причин живучести вероятностно-статистических моделей на основе нормального распределения. Такие модели, как правило, неадекватны реальной ситуации [6, глава 4.1]. Однако с математической точки зрения они позволяют глубже проникнуть в суть изучаемого явления. Поэтому такие модели полезны для первоначального анализа ситуации. В ходе дальнейших исследований необходимо снять нереалистическое предположение нормальности и перейти к непараметрическим моделям. В прикладной статистике часто используют следующую технологию анализа данных. Сначала пытаются применить модель (5) для линейной функции (m = 1), при неудаче (неадекватности модели) переходят к многочлену второго порядка (m = 2), если снова неудача, то берут модель (2) с m= 3 и т.д. Адекватность модели обычно проверяют по F-критерию Фишера. Обсудим свойства этой процедуры. Если степень полинома задана (m = m0), то его коэффициенты оценивают методом наименьших квадратов, свойства этих оценок хорошо известны. Однако в рассматриваемой постановке mтоже является неизвестным параметром и подлежит оценке. Таким образом, требуется оценить объект (m, a0, a1, a2, …,am), множество значений которого можно описать как Оценивание степени полинома. Полезно рассмотреть основной показатель качества регрессионной модели (5). Одни и те же данные можно обрабатывать различными способами. На первый взгляд, показателем отклонений данных от модели может служить остаточная сумма квадратов SS. Чем этот показатель меньше, тем приближение лучше, значит, и модель лучше описывает реальные данные. Однако это рассуждение годится только для моделей с одинаковым числом параметров. Ведь если добавляется новый параметр, по которому можно минимизировать, то и минимум, как правило, оказывается меньше. В качестве основного показателя качества регрессионной модели используют следующую оценку остаточной дисперсии
Таким образом, вводят корректировку на число параметров, оцениваемых по наблюдаемым данным. Корректировка состоит в уменьшении знаменателя на указанное число. В модели (5) это число равно (m+1). В случае задачи восстановления линейной функции одной переменной оценка остаточной дисперсии имеет вид
поскольку число оцениваемых параметров m + 1 =2. Еще раз - почему при подборе вида модели знаменатель дроби, оценивающей остаточную дисперсию, приходится корректировать на число параметров? Если этого не делать, то придется заключить, что всегда многочлен второй степени лучше соответствует данным, чем линейная функция, многочлен третьей степени лучше приближает исходные данные, чем многочлен второй степени, и т.д. В конце концов доходим до многочлена степени (n-1) с nкоэффициентами, который проходит через все заданные точки. Но его прогностические возможности, скорее всего, существенно меньше, чем даже у линейной функции. Излишнее усложнение статистических моделей вредно. Типовое поведение скорректированной оценки остаточной дисперсии
в случае расширяющейся системы моделей (т.е. при возрастании натурального параметра m) выглядит так. Сначала наблюдаем заметное убывание. Затем оценка остаточной дисперсии колеблется около некоторой константы (дисперсии погрешности). Поясним ситуацию на примере модели восстановления зависимости, выраженной многочленом:
Пусть эта модель справедлива при
Следовательно, скорректированная оценка остаточной дисперсии будет колебаться около указанного предела. Поэтому представляется естественным, что в качестве оценки неизвестной статистику степени многочлена (полинома) можно использовать первый локальный минимум скорректированной оценки остаточной дисперсии, т.е.
В работе [40] найдено предельное распределение этой оценки степени многочлена. Теорема. При справедливости некоторых условий регулярности
где
Таким образом, предельное распределение оценки m* степени многочлена (полинома) является геометрическим. Это означает, в частности, что оценка не является состоятельной. При этом вероятность получить меньшее значение, чем истинное, исчезающе мала. Далее имеем:
Разработаны и иные методы оценивания неизвестной степени многочлена, например, путем многократного применения процедуры проверки адекватности регрессионной зависимости с помощью критерия Фишера. Предельное поведение таких оценок - таково же, как в приведенной выше теореме, только значение параметра Построение информативного подмножества признаков. В более общем случае многомерной линейной регрессии данные имеют вид
(здесь K - некоторое подмножество множества {1,2,…,n}; Модель (5) сводится к модели (6), если
В модели (5) есть естественный порядок ввода предикторов в рассмотрение - в соответствии с возрастанием степени многочлена, а в модели (6) естественного порядка нет, поэтому здесь приходится рассматривать произвольное подмножество множества предикторов. Есть только частичный порядок - чем мощность подмножества меньше, тем лучше. Модель (6) особенно актуальна в технических исследованиях (см. многочисленные примеры в журнале «Заводская лаборатория»). Она применяется в задачах управления качеством продукции и других технико-экономических исследованиях, в медицине, экономике, маркетинге и социологии, когда из большого числа факторов, предположительно влияющих на изучаемую переменную, надо отобрать по возможности наименьшее число значимых факторов и с их помощью сконструировать прогнозирующую формулу (6). Задача оценивания модели (6) разбивается на две последовательные задачи: оценивание множества K - подмножества множества всех предикторов, а затем - неизвестных параметров aj. Методы решения второй задачи хорошо известны и подробно изучены (обычно используют метод наименьших квадратов). Гораздо хуже обстоит дело с оцениванием объекта нечисловой природы K. Как уже отмечалось, существующие методы - в основном эвристические, они зачастую не являются даже состоятельными. Даже само понятие состоятельности в данном случае требует специального определения. Определение. Пусть K0 - истинное подмножество предикторов, т.е. подмножество, для которого справедлива модель (6), а подмножество предикторов Kn - его оценка. Оценка Kn называется состоятельной, если
где Δ - символ симметрической разности множеств; Card(K) означает число элементов множества K, а предел понимается в смысле сходимости по вероятности. Задача оценивания в моделях регрессии, таким образом, разбивается на две - оценивание структуры модели и оценивание параметров при заданной структуре. В модели (5) структура описывается неотрицательным целым числомm, в модели (6) - множеством K. Структура - объект нечисловой природы. Задача ее оценивания сложна, в то время как задача оценивания численных параметров при заданной структуре хорошо изучена, разработаны эффективные (в смысле прикладной математической статистики) методы. Такова же ситуация и в других методах многомерного статистического анализа - в факторном анализе (включая метод главных компонент) и в многомерном шкалировании, в иных оптимизационных постановках проблем прикладного многомерного статистического анализа. Множество K и параметры aj линейной зависимости можно оценивать путем решения задачи оптимизации
в которой минимум берется по K, aj,
|
||
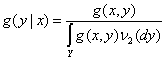 (3)
(3)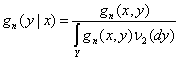 . (4)
. (4)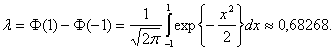
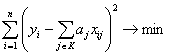 , (7)
, (7)