«Управление и Оптимизация Производственного Предприятия»
|
|
|
|
|
М.: МЗ-Пресс, 2004. Глава 2. Статистические методы в пространствах произвольной природы 2.8. Методы классификации Как известно, математический аппарат нечисловой статистики базируется на использовании расстояний (мер близости, показателей различия) в пространствах таких объектов. Это вызвано отсутствием в таких пространствах операций суммирования, на которых основано большинство методов других областей статистики. Любые методы, использующие только расстояния (меры близости, показатели различия) между объектами, следует относить к нечисловой статистике, поскольку такие методы могут работать с объектами произвольного пространства, если в нем задана метрика или ее аналоги. Таким образом, весьма многие методы классической прикладной статистики следует включать в нечисловую статистику. В настоящем разделе рассматривается важное направление прикладной статистики – математические методы классификации. Значительную их часть следует отнести к нечисловой статистике, а именно, методы классификации, основанные на расстояниях между объектами. Основные направления в математической теории классификации. Какие научные исследования относить к этой теории? Исходя из потребностей специалиста, применяющего математические методы классификации, целесообразно принять, что сюда входят исследования, во-первых, отнесенные самими авторами к этой теории; во вторых, связанные с ней общностью тематики, хотя бы их авторы и не упоминали термин «классификация». В литературных источниках наряду с термином «классификация» в близких смыслах используются термины «группировка», «распознавание образов», «диагностика», «дискриминация», «сортировка», «типология», «систематика», «районирование», «сегментирование» и др. Терминологический разнобой связан прежде всего с традициями научных кланов, к которым относятся авторы публикаций, а также с внутренним делением самой теории классификации. В научных исследованиях по современной теории классификации можно выделить два относительно самостоятельных направления. Одно из них опирается на опыт таких наук, как биология, география, геология, и таких прикладных областей, как ведение классификаторов продукции и библиотечное дело. Типичные объекты рассмотрения - классификация химических элементов (таблица Д.И. Менделеева), биологическая систематика, универсальная десятичная классификация публикаций (УДК), классификатор товаров на основе штрих-кодов. Другое направление опирается на опыт технических исследований, экономики, маркетинговых исследований, социологии, медицины. Типичные задачи - техническая и медицинская диагностика, а также, например, разбиение на группы отраслей промышленности, тесно связанных между собой, выделение групп однородной продукции. Обычно используются такие термины, как «распознавание образов», «кластер-анализ» или «дискриминантный анализ». Это направление обычно опирается на математические модели; для проведения расчетов интенсивно используется ЭВМ. В 60-х годах XX века внутри статистических методов достаточно четко оформилась область, посвященная методам классификации. Несколько модифицируя формулировки М. Дж. Кендалла и А. Стьюарта 1966 г. (см. русский перевод [43, с.437]), в теории классификации выделим три подобласти: дискриминация (дискриминантный анализ), кластеризация (кластер-анализ), группировка. Опишем эти подобласти. В дискриминантном анализе классы предполагаются заданными - плотностями вероятностей или обучающими выборками. Задача состоит в том, чтобы вновь поступающий объект отнести в один из этих классов. У понятия «дискриминация» имеется много синонимов: диагностика, распознавание образов с учителем, автоматическая классификация с учителем, статистическая классификация и т.д. При кластеризации и группировке целью является выявление и выделение классов. Синонимы: построение классификации, распознавание образов без учителя, автоматическая классификация без учителя, типология, таксономия и др. При этом задача кластер-анализа состоит в выяснении по эмпирическим данным, насколько элементы "группируются" или распадаются на изолированные "скопления", "кластеры" (от cluster (англ.) - гроздь, скопление). Иными словами, задача - выявление естественного разбиения на классы, свободного от субъективизма исследователя, а цель - выделение групп однородных объектов, сходных между собой, при резком отличии этих групп друг от друга. При группировке, наоборот, «мы хотим разбить элементы на группы независимо от того, естественны ли границы разбиения или нет» [43, с.437]. Цель по-прежнему состоит в выявлении групп однородных объектов, сходных между собой (как в кластер-анализе), однако «соседние» группы могут не иметь резких различий (в отличие от кластер-анализа). Границы между группами условны, не являются естественными, зависят от субъективизма исследователя. Аналогично при лесоустройстве проведение просек (границ участков) зависит от специалистов лесного ведомства, а не от свойств леса. Задачи кластеризации и группировки принципиально различны, хотя для их решения могут применяться одни и те же алгоритмы. Важная для практической деятельности проблема состоит в том, чтобы понять, разрешима ли задача кластер-анализа для конкретных данных или возможна только их группировка, поскольку совокупность объектов достаточно однородна и не разбивается на резко разделяющиеся между собой кластеры. Как правило, в математических задачах кластеризации и группировки основное - выбор метрики, расстояния между объектами, меры близости, сходства, различия. Хорошо известно, что для любого заданного разбиения объектов на группы и любого положительного числа e > 0 можно указать метрику такую, что расстояния между объектами из одной группы будут меньше e, а между объектами из разных групп - больше 1/e. Тогда любой разумный алгоритм кластеризации даст именно заданное разбиение. Понимание и обсуждение постановок задач осложняется использованием одного и того же термина в разных смыслах. Термином "классификация" (и сходными терминами, такими, как "диагностика") обозначают по крайней мере три разные сущности. Во-первых, процедуру построения классификации (и выделение классов, используемых при диагностике). Во-вторых, построенную классификацию (систему выделенных классов). В-третьих, процедуру ее использования (правила отнесения вновь поступающего объекта к одному из ранее выделенных классов). Другими словами, имеем естественную триаду: построение – изучение – использование классификации. Как уже отмечалось, для построения системы диагностических классов используют разнообразные методы кластерного анализа и группировки объектов. Наименее известен второй член триады (отсутствующий у Кендалла и Стьюарта [43]) – изучение отношений эквивалентности, полученных в результате построения системы диагностических классов. Статистический анализ полученных, в частности экспертами, отношений эквивалентности - часть статистики бинарных отношений и тем самым - нечисловой статистики (см. главу 3). Диагностика в узком смысле слова (процедура использования классификации, т.е. отнесения вновь поступающего объекта к одному из выделенных ранее классов) - предмет дискриминантного анализа. Отметим, что с точки зрения нечисловой статистики дискриминантный анализ является частным случаем общей схемы регрессионного анализа, соответствующим ситуации, когда зависимая переменная принимает конечное число значений, а именно - номера классов, а вместо квадрата разности стоит функция потерь от неправильной классификации. Однако есть ряд специфических постановок и методов принятия решений, выделяющих задачи диагностики среди всех регрессионных задач. О построении диагностических правил. Начнем с краткого обсуждения одного распространенного заблуждения. Предположим, что исходные статистические данные явно неоднородны. Иногда рекомендуют сначала построить систему диагностических классов (т.е. кластеров), а потом в каждом диагностическом классе отдельно проводить регрессионный анализ или применять иные статистические методы.. Однако обычно забывают, что при этом нельзя опираться на вероятностную модель многомерного нормального распределения, так как распределение результатов наблюдений, попавших в определенный кластер, будет отнюдь не нормальным, а усеченным нормальным (усечение определяется фиксированными границами кластера) или более сложным (если границы кластера случайны). Одна из возможных рекомендаций [44] - применять в таких случаях робастные методы восстановления зависимостей. Состоятельная оценка числа классов. Процедуры построения диагностических правил делятся на вероятностные и детерминированные. К первым относятся так называемые задачи расщепления смесей. В них предполагается, что распределение вновь поступающего случайного элемента является смесью вероятностных законов, соответствующих диагностическим классам. Как и при выборе степени полинома в регрессии (см. предыдущий раздел), при анализе реальных статистических данных (технических, социально-экономических, медицинских и др.) встает вопрос об оценке числа элементов смеси, т.е. числа диагностических классов. Были изучены результаты применения обычно рекомендуемого критерия Уилкса для оценки числа элементов смеси. Оказалось (см. статью [44]), что оценка с помощью известного критерия Уилкса не является состоятельной, асимптотическое распределение этой оценки – геометрическое, как и в случае задачи восстановления зависимости в регрессионном анализе. Итак, в [44] продемонстрирована несостоятельность обычно используемых оценок. Для получения состоятельных оценок достаточно связать уровень значимости в критерии Уилкса с объемом выборки, как это было предложено и для задач регрессии [40, 41]. Таким образом, разработаны состоятельные оценки такого нечислового объекта, как число классов. Как уже отмечалось, задачи построения системы диагностических классов целесообразно разбить на два типа - с четко разделенными кластерами (задачи кластер-анализа) и с условными границами, непрерывно переходящими друг в друга классами (задачи группировки). Такое деление полезно, хотя в обоих случаях могут применяться одинаковые алгоритмы. Сколько существует алгоритмов построения системы диагностических правил? Иногда называют то или иное число. На самом же деле их бесконечно много, в чем нетрудно убедиться. Действительно, рассмотрим один определенный алгоритм - алгоритм средней связи. Он основан на использовании некоторой меры близости d(x,y) между объектами x и у. Как он работает? На первом шаге каждый объект рассматривается как отдельный кластер. На каждом следующем шаге объединяются две ближайших кластера. Расстояние между объектами рассчитывается как средняя связь (отсюда и название алгоритма), т.е. как среднее арифметическое расстояний между парами объектов, один из которых входит в первый кластер, а другой - во второй. В конце концов все объекты объединяются вместе, и результат работы алгоритма представляет собой дерево последовательных объединений (в терминах теории графов), или "Дендрограмму". Из нее можно выделить кластеры разными способами. Один подход - исходя из заданного числа кластеров. Другой - из соображений предметной области. Третий - исходя из устойчивости (если разбиение долго не менялось при возрастании порога объединения – значит, оно отражает реальность). И т.д. К алгоритму средней связи естественно сразу добавить алгоритм ближайшего соседа. В этом алгоритме расстоянием между кластерами называется минимальное из расстояний между парами объектов, один из которых входит в первый кластер, а другой - во второй. А также и алгоритм дальнего соседа (когда расстоянием между кластерами называется максимальное из расстояний между парами объектов, один из которых входит в первый кластер, а другой - во второй). Каждый из трех описанных алгоритмов (средней связи, ближайшего соседа, дальнего соседа), как легко проверить, порождает бесконечное (континуальное) семейство алгоритмов кластер-анализа. Дело в том, что величинаda(x,y), a>0, также является мерой близости между x и у и порождает новый алгоритм. Если параметр а пробегает отрезок, то получается бесконечно много алгоритмов классификации. Устойчивость - критерий естественности классификации. Каким из них пользоваться при обработке данных? Дело осложняется тем, что практически в любом пространстве статистических данных существует весьма много мер близости различных видов. Именно в связи с обсуждаемой проблемой следует указать на принципиальное различие между кластер-анализом и задачами группировки. Если классы реальны, естественны, существуют на самом деле, четко отделены друг от друга, то любой алгоритм кластер-анализа их выделит. Следовательно, в качестве критерия естественности классификации следует рассматривать устойчивость результата классификации относительно выбора алгоритма кластер-анализа. Проверить устойчивость можно, применив к одним и тем же данным несколько подходов, например, столь непохожие алгоритмы, как «ближнего соседа» и «дальнего соседа». Если полученные результаты содержательно близки, то они адекватны действительности. В противном случае следует предположить, что естественной классификации не существует, задача кластер-анализа не имеет решения, и можно проводить только группировку. Как уже отмечалось, часто применяется т.н. агломеративный иерархический алгоритм "Дендрограмма", в котором вначале все элементы рассматриваются как отдельные кластеры, а затем на каждом шагу объединяются два наиболее близких кластера. Для работы «Дендрограммы» необходимо задать правило вычисления расстояния между кластерами. Оно вычисляется через расстояние d(x,у) между элементами х и у. Поскольку da(x,y) при 0<a<1 также расстояние, то, как правило, существует бесконечно много различных вариантов этого алгоритма. Представим себе, что они применяются для обработки одних и тех же реальных данных. Если при всех а получается одинаковое разбиение элементов на кластеры, т.е. результат работы алгоритма устойчив по отношению к изменению а (в смысле общей схемы устойчивости, введенной в [1]), то имеем «естественную» классификацию. В противном случае результат зависит от субъективно выбранного исследователем параметра а, т.е. задача кластер-анализа неразрешима (предполагаем, что выбор а нельзя специально обосновать). Задача группировки в этой ситуации имеет много решений. Из них можно выбрать одно по дополнительным критериям. Следовательно, получаем эвристический критерий: если решение задачи кластер-анализа существует, то оно находится с помощью любого алгоритма. Целесообразно использовать наиболее простой. Продолжим обсуждение в более широком контексте. Проблема поиска естественной классификации. Существуют различные точки зрения на эту проблему. Естественная классификация обычно противопоставляется искусственной. На Всесоюзной школе-семинаре «Использование математических методов в задачах классификации» (г. Пущино, 1986 г.), в частности, были высказаны мнения, что естественная классификация: - закон природы; - основана на глубоких закономерностях, тогда как искусственная классификация - на неглубоких; - для конкретного индивида та, которая наиболее быстро вытекает из его тезауруса; - удовлетворяет многим целям; цель искусственной классификации задает человек; - классификация с точки зрения потребителя продукции; - классификация, позволяющая делать прогнозы; - имеет критерием устойчивость. Приведенные высказывания уже дают представление о больших расхождениях в понимании «естественной классификации». Этот термин следует признать нечетким, как, впрочем, и многие другие термины, и профессиональные - социально-экономические, научно-технические, и используемые в обыденном языке. Нетрудно подробно обоснована нечеткость естественного языка и тот факт, что "мы мыслим нечетко", что, однако, не слишком мешает нам решать производственные и жизненные проблемы. Кажущееся рациональным требование выработать сначала строгие определения, а потом развивать науку - невыполнимо. Следовать ему - значит отвлекать силы от реальных задач. При системном подходе к теории классификации становится ясно, что строгие определения можно надеяться получить на последних этапах построения теории. Мы же сейчас находимся на первых этапах. Поэтому, не давая строгого определения понятиям «естественная классификация» и «естественная диагностика», обсудим, как проверить на «естественность» полученную расчетным путем классификацию (набор диагностических классов). Можно выделить два критерия «естественности», по поводу которых имеется относительное согласие: А. Естественная классификация должна быть реальной, соответствующей действительному миру, лишенной внесенного исследователем субъективизма; Б. Естественная классификация должна быть важной или с научной точки зрения (давать возможность прогноза, предсказания новых свойств, сжатия информации и т.д.), или с практической. Пусть классификация проводится на основе информации об объектах, представленной в виде матрицы «объект-признак» или матрицы попарных расстояний (мер близости). Пусть алгоритм классификации дал разбиение на кластеры. Как можно получить доводы в пользу естественности этой классификации? Например, уверенность в том, что она - закон природы, может появиться только в результате ее длительного изучения и практического применения. Это соображение относится и к другим из перечисленных выше критериев, в частности к Б (важности). Сосредоточимся на критерии А (реальности). Понятие «реальности» кластера требует специального обсуждения. (оно начато в работе [44]). Рассмотрим существо различий между понятиями «классификация» (как результат кластер-анализа) и «группировка». Пусть, к примеру, необходимо деревья, растущие в определенной местности, разбить на группы находящихся рядом друг с другом. Ясна интуитивная разница между несколькими отдельными рощами, далеко отстоящими друг от друга и разделенными полями, и сплошным лесом, разбитым просеками на квадраты с целью лесоустройства. Однако формально определить эту разницу столь же сложно, как определить понятие «куча зерен», чем занимались еще в Древней Греции. Ясно, что одно зерно не составляет кучи, два зерна не составляют кучи,… Если к тому, что не составляет кучи, добавить еще одно зерно, то куча не получится. Значит - по принципу математической индукции - никакое количество зерен не составляет кучи. Но ясно, что миллиард зерен - большая куча зерен - подсчитайте объем! (Этот пример французского математика Э. Бореля (1871 - 1956) относится к теории нечеткости.) Переформулируем сказанное в терминах "кластер-анализа" и "методов группировки". Выделенные с помощью первого подхода кластеры реальны, а потому могут рассматриваться как кандидаты в "естественные". Группировка дает "искусственные" классы, которые не могут быть "естественными". Выборку из унимодального распределения можно, видимо, рассматривать как "естественный", "реальный" кластер. Применим к ней какой-либо алгоритм классификации ("средней связи", "ближайшего соседа" и т.п.). Он даст какое-то разбиение на классы, которые, разумеется, не являются "реальными", поскольку отражают прежде всего свойства алгоритма, а не исходных данных. Как отличить такую ситуацию от противоположной, когда имеются реальные кластеры и алгоритм классификации более или менее точно их выделяет? Как известно, "критерий истины – практика", но слишком много времени необходимо для применения подобного критерия. Поэтому представляет интерес критерий, оценивающий "реальность" выделяемых с помощью алгоритма классификации кластеров одновременно с его применением. Такой показатель существует - это критерий устойчивости. Устойчивость - понятие широкое. Общая схема формулирования и изучения проблем устойчивости рассмотрена в [1]. В частности, поскольку значения признаков всегда измеряются с погрешностями, то "реальное" разбиение должно быть устойчиво (т.е. не меняться или меняться слабо) при малых отклонениях исходных данных. Алгоритмов классификации существует бесконечно много, и "реальное" разбиение должно быть устойчиво по отношению к переходу к другому алгоритму. Другими словами, если "реальное" разбиение на классы возможно, то оно находится с помощью любого алгоритма автоматической классификация. Следовательно, критерием естественности классификации может служить совпадение результатов работы двух достаточно различающихся алгоритмов, например "ближайшего соседа" и "дальнего соседа". Критерии «естественности» кластеров и классификаций. Выше рассмотрены два типа "глобальных" критериев "естественности классификации", касающихся разбиения в целом. «Локальные» критерии относятся к отдельным кластерам. Простейшая постановка такова: достаточно ли однородны два кластера (две совокупности) для их объединения:? Если объединение возможно, то кластеры не являются "естественными". Преимущество этой постановки в том, что она допускает применение статистических критериев однородности двух выборок. В одномерном случае (классификация по одному признаку) разработано большое число подобных критериев — Крамера-Уэлча, Смирнова, омега-квадрат (Лемана - Розенблатта), Вилкоксона, Ван-дер-Вардена, Лорда, Стьюдента и др. [6, 30]. Имеются критерии и для многомерных данных. Для одного из видов объектов нечисловой природы - люсианов - статистические методы выделения "реальных" кластеров развиты в разделе 3.4. Что касается глобальных критериев, то для изучения устойчивости по отношению к малым отклонениям исходных данных естественно использовать метод статистических испытаний и проводить расчеты по "возмущенным" данным. Некоторые теоретические утверждения, касающиеся влияния «возмущений» на кластеры различных типов, получены в работе [44]. Опишем практический опыт реализации анализа устойчивости. Несколько алгоритмов классификации были применены к данным, полученным при проведении маркетинга образовательных услуг и приведенным в работе [45]. Для анализа данных были использованы широко известные алгоритмы "ближайшего соседа", "дальнего соседа" и алгоритм кластер-анализа из работы [46]. С содержательной точки зрения полученные разбиения отличались мало. Поэтому есть основания считать, что с помощью этих алгоритмов действительно выявлена «реальная» структура данных. Идея устойчивости как критерия "реальности" иногда реализуется неадекватно. Так, для однопараметрических алгоритмов иногда предлагают выделять разбиения, которым соответствуют наибольшие интервалы устойчивости по параметру, т.е. наибольшие приращения параметра между очередными объединениями кластеров. Для данных работы [45] это предложение не дало полезных результатов - были получены различные разбиения: три алгоритма - три разбиения. И с теоретической точки зрения предложение этого специалиста несостоятельно. Покажем это. Действительно, рассмотрим алгоритм "ближайшего соседа", использующий меру близости d(x,у), и однопараметрическое семейство алгоритмов с мерой близости da(x,y), а>0, также являющихся алгоритмами "ближайшего соседа". Тогда дендрограммы, полученные с помощью этих алгоритмов, совпадают при всех a, поскольку при их реализации происходит лишь сравнение мер близости между объектами. Другими словами, дендрограмма, полученная с помощью алгоритма «ближайшего соседа», является адекватной в порядковой шкале (измерения меры близости d(x,у)), т.е. сохраняется при любом строго возрастающем преобразовании этой меры. Однако выделенные по обсуждаемому методу "устойчивые разбиения" меняются, другими словами, не являются адекватными в порядковой шкале. В частности, при достаточно большом а "наиболее объективным" в соответствии с рассматриваемым предложением будет, как нетрудно показать, разбиение на два кластера! Таким образом, разбиение, выдвинутое им как "устойчивое", на самом деле оказывается весьма неустойчивым. Рассмотрим с позиций нечисловой статистики несколько конкретных вопросов теории классификации. Вероятностная теория кластер-анализа. Как и для прочих статистических методов, свойства алгоритмов кластер-анализа необходимо изучать на вероятностных моделях. Это касается, например, условий естественного объединения двух кластеров. Вероятностные постановки нужно применять, в частности, при перенесении результатов, полученных по выборке, на генеральную совокупность. Вероятностная теория кластер-анализа и методов группировки различна для исходных данных типа таблиц «объект Ч признак» и матриц сходства. Для первых параметрическая вероятностно-статистическая теория называется "расщеплением смесей". Непараметрическая теория основана на непараметрических оценках плотностей вероятностей и их мод. Основные результаты, связанные с непараметрическими оценками плотности, обсуждались в разделе 2.5. Если исходные данные - матрица сходства ||d(x,y)||, то необходимо признать, что развитой вероятностно-статистической теории пока нет. Подходы к ее построению намечены в работе [44]. Одна из основных проблем - проверка "реальности" кластера, его объективного существования независимо от расчетов исследователя. Проблема "реальности" кластера давно обсуждается специалистами различных областей. Типичное рассуждение, напомним, таково. Предположим, что результаты наблюдений можно рассматривать как выборку из некоторого распределения с монотонно убывающей плотностью при увеличении расстояния от некоторого центра. Примененный к подобным данным какой-либо алгоритм кластер-анализа порождает некоторое разбиение. Ясно, что оно - чисто формальное, поскольку выделенным таксонам (кластерам) не соответствуют никакие "реальные" классы. Другими словами, задача кластер-анализа не имеет решения, а алгоритм дает лишь группировку. При обработке реальных данных мы не знаем вида плотности. Проблема состоит в том, чтобы определить, каков результат работы алгоритма (реальные кластеры или формальные группы). Частный случай этой проблемы - проверка обоснованности объединения двух кластеров, которые мы рассматриваем как два множества объектов, а именно, множества {a1, a2,…, ak} и {b1, b2,…, bm}. Пусть, например, используется алгоритм типа "Дендрограмма". Естественной представляется следующая идея. Пусть есть две совокупности мер близости. Одна - меры близости между объектами, лежащими внутри одного кластера, т.е. d(ai,aj),1<i<j<k, d(ba,bb), 1<a<b<m. Другая совокупность - меры близости между объектами, лежащими в разных кластерах, т.е. d(ai,ba), 1<i<k, 1<a<m. Эти две совокупности мер близости предлагается рассматривать как независимые выборки и проверять гипотезу о совпадении их функций распределения. Если гипотеза не отвергается, объединение кластеров считается обоснованным; в противном случае - объединять нельзя, алгоритм прекращает работу. В рассматриваемом подходе есть две некорректности (см. также работу [44, разд.4]). Во-первых, меры близости не являются независимыми случайными величинами. Во-вторых, не учитывается, что объединяются не заранее фиксированные кластеры (с детерминированным составом), а полученные в результате работы некоторого алгоритма, и их состав (в частности, количество элементов) оказывается случайным. От первой из этих некорректностей можно частично избавиться. Справедливо следующее утверждение [47]. Теорема 1. Пусть a1, a2,…, ak, b1, b2,…, bm - независимые одинаково распределенные случайные величины (со значениями в произвольном пространстве). Пусть случайная величина d(а1,а2) имеет все моменты. Тогда при k, т®¥ распределение статистики
сходится к стандартному нормальному распределению с математическим ожиданием 0 и дисперсией 1. Здесь U -сумма рангов элементов первой выборки в объединенной выборке; первая выборка составлена из внутрикластерных расстояний (мер близости) d(ai,aj), 1<i<j<k, и d(ba,bb), 1<a<b<m, а вторая - из межкластерных расстояний d(ai,ba),1<i<k, 1<a<m. На основе теоремы 1 очевидным образом формулируется правило проверки обоснованности объединения двух кластеров. Другими словами, мы проверяем статистическую гипотезу, согласно которой объединение двух кластеров образует однородную совокупность. Если величина U слишком мала, статистическая гипотеза однородности отклоняется (на заданном уровне значимости), и возможность объединения отбрасывается. Таким образом, хотя расстояния между объектами в кластерах зависимы, но эта зависимость слаба, и доказана математическая теорема о допустимости применения критерия Вилкоксона для проверки возможности объединения кластеров. О вычислительной сходимости алгоритмов кластер-анализа. Алгоритмы кластер-анализа и группировки зачастую являются итерационными. Например, формулируется правило улучшения решения задачи кластер-анализа шаг за шагом, но момент остановки вычислений не обсуждается. Примером является известный алгоритм "Форель", в котором постепенно улучшается положение центра кластера. В этом алгоритме на каждом шаге строится шар определенного заранее радиуса, выделяются элементы кластеризуемой совокупности, попадающие в этот шар, и новый центр кластера строится как центр тяжести выделенных элементов. При анализе алгоритма «Форель» возникает проблема: завершится ли процесс улучшения положения центра кластера через конечное число шагов или же он может быть бесконечным. Она получила название «проблема остановки». Для широкого класса так называемых "эталонных алгоритмов" проблема остановки была решена в работе [44]: процесс улучшения остановится через конечное число шагов. Отметим, что алгоритмы кластер-анализа могут быть модифицированы разнообразными способами. Например, описывая алгоритм "Форель" в стиле статистики объектов нечисловой природы, заметим, что вычисление центра тяжести для совокупности многомерных точек – это нахождение эмпирического среднего для меры близости, равной квадрату евклидова расстояния. Если взять более естественную меру близости – само евклидово расстояние, то получим алгоритм кластер-анализа "Медиана", отличающийся от "Форели" тем, что новый центр кластера строится не с помощью средних арифметических координат элементов, попавших в кластер, а с помощью медиан. Проблема остановки возникает не только при построении диагностических классов. Она принципиально важна, в частности, и при оценивании параметров вероятностных распределений методом максимального правдоподобия. Обычно не представляет большого труда выписать систему уравнений максимального правдоподобия и предложить решать ее каким-либо численным методом. Однако когда остановиться, сколько итераций сделать, какая точность оценивания будет при этом достигнута? Общий ответ, видимо, невозможно найти, но обычно нет ответа и для конкретных семейств распределения вероятностей. Именно поэтому нет оснований рекомендовать решать системы уравнений максимального правдоподобия. Вместо них целесообразно использовать т.н. одношаговые оценки (подробнее об этих оценках см. раздел 2.4). Эти оценки задаются конечными формулами, но асимптотически столь же хороши (на профессиональном языке - эффективны), как и оценки максимального правдоподобия. О сравнении алгоритмов диагностики по результатам обработки реальных данных. Перейдем к этапу применения диагностических правил, когда классы, к одному из которых нужно отнести вновь поступающий объект, уже выделены. В прикладных исследованиях применяют различные методы дискриминантного анализа, основанные на вероятностно-статистических моделях, а также с ними не связанные, т.е. эвристические, использующие детерминированные методы анализа данных. Независимо от "происхождения", каждый подобный алгоритм должен быть исследован как на параметрических и непараметрических вероятностно-статистических моделях порождения данных, так и на различных массивах реальных данных. Цель исследования - выбор наилучшего алгоритма в определенной области применения, включение его в стандартные программные продукты, методические материалы, учебные программы и пособия. Но для этого надо уметь сравнивать алгоритмы по качеству. Как это делать? Часто используют такой показатель качества алгоритма диагностики, как "вероятность правильной классификации" (при обработке конкретных данных - "частота правильной классификации"). Чуть ниже мы покажем, что этот показатель качества некорректен, а потому пользоваться им не рекомендуется. Целесообразно применять другой показатель качества алгоритма диагностики - оценку специального вида т.н. "расстояния Махаланобиса" между классами. Изложение проведем на примере разработки программного продукта для специалистов по диагностике материалов. Прообразом является диалоговая система «АРМ материаловеда», разработанная Институтом высоких статистических технологий и эконометрики для ВНИИ эластомерных материалов (Москва). При построении информационно-исследовательской системы диагностики материалов (ИИСДМ) возникает задача сравнения прогностических правил «по силе». Прогностическое правило - это алгоритм, позволяющий по характеристикам материала прогнозировать его свойства. Если прогноз дихотомичен («есть» или «нет»), то правило является алгоритмом диагностики, при котором материал относится к одному из двух классов. Ясно, что случай нескольких классов может быть сведен к конечной последовательности выбора между двумя классами. Прогностические правила могут быть извлечены из научно-технической литературы и практики. Каждое из них обычно формулируется в терминах небольшого числа признаков, но наборы признаков сильно меняются от правила к правилу. Поскольку в ИИСДМ должно фиксироваться лишь ограниченное число признаков, то возникает проблема их отбора. Естественно отбирать лишь те их них, которые входят в наборы, дающие наиболее «надежные» прогнозы. Для придания точного смысла термину «надежный» необходимо иметь способ сравнения алгоритмов диагностики по прогностической "силе". Результаты обработки реальных данных с помощью некоторого алгоритма диагностики в рассматриваемом случае двух классов описываются долями: правильной диагностики в первом классе При изучении качества алгоритмов классификации их сравнивают по результатам дискриминации вновь поступающей контрольной выборки. А именно, по контрольной выборке определяются величины Нецелесообразность применения «доли правильной диагностики». Нередко как показатель качества алгоритма диагностики (прогностической «силы») используют долю правильной диагностики
Однако показатель Другими словами, по доле правильной классификации алгоритм академика И.М. Гельфанда оказался хуже тривиального - объявить всех больных легкими, не требующими специального наблюдения. Этот вывод (о преимуществе тривиального прогноза), очевидно, нелеп. И причина появления нелепости вполне понятна. Хотя доля тяжелых больных невелика, но смертельные исходы сосредоточены именно в этой группе больных. Поэтому целесообразна гипердиагностика - рациональнее часть легких больных объявить тяжелыми, чем сделать ошибку в противоположную сторону. Применение теории статистических решений в рассматриваемой постановке вряд ли возможно, поскольку оценить количественно потери от смерти больного нельзя по этическим соображениям. Поэтому, на наш взгляд, долю правильной диагностики Поясним сказанное. Применение теории статистических решений требует знания потерь от ошибочной диагностики, а в большинстве научно-технических и экономических задач определить потери, как уже отмечалось, сложно. В частности, из-за необходимости оценивать человеческую жизнь в денежных единицах. По этическим соображениям это, на наш взгляд, недопустимо. Сказанное не означает отрицания пользы страхования, но, очевидно, страховые выплаты следует рассматривать лишь как способ первоначального смягчения потерь от утраты близких. Метод нормального усреднения. Для выявления информативного набора признаков целесообразно использовать метод нормального усреднения. Его называют также методом пересчета на модель линейного дискриминантного анализа. Согласно этому методу статистической оценкой прогностической "силы" является
где Пример 1. Если доли правильной классификации κ = 0,90 и λ = 0,80, то Φ-1(κ) = 1,28 и Φ-1(λ) = 0,84, откуда d*= 2,12 и прогностическая сила δ* = Φ-1(1,06) = 0,86. При этом доля правильной классификации μ может принимать любые значения между 0,80 и 0,90, в зависимости от доли элементов того или иного класса среди анализируемых данных. Если классы описываются выборками из многомерных нормальных совокупностей с одинаковыми матрицами ковариаций, а для классификации применяется классический линейный дискриминантный анализ Р.Фишера, то величина Пусть алгоритм классификации применялся к совокупности, состоящей из т объектов первого класса и nобъектов второго класса. Теорема 2 [47]. Пусть т, п®¥. Тогда для всех х
где - истинная "прогностическая сила" алгоритма диагностики; ;
С помощью теоремы 2 по Пример 2. В условиях примера 1 при m = n = 100 найдем асимптотическое среднее квадратическое отклонениеА(0,90; 0,80). Поскольку φ(Φ-1(κ)) = φ(1,28) = 0,176, φ(Φ-1(λ)) = φ(0,84) = 0,280, φ(d*/2) = φ(1,06) = 0,227, то подставляя в выражение для А2 численные значения, получаем, что
(численные значения плотности стандартного нормального распределения с математическим ожиданием 0 и дисперсией 1 и функции, обратной к функции этого распределения, можно было взять, например, из справочника [30]). При m = n = 100 имеем А(0,90; 0,80) = 0,0252. При доверительной вероятности γ = 0,95 имеем u(0,95) = Φ-1(1,0,975) = 1,96, а потому нижняя доверительная граница для прогностической силы δ есть δН = 0,86 – 1,96 Ч 0,0252 = 0,81, а верхняя доверительная граница такова: δВ = 0,86 + 1,96 Ч 0,0252 = 0,91. Аналогичный расчет при m =n = 1000 дает δН = 0,845, δВ = 0,875. Как проверить обоснованность пересчета на модель линейного дискриминантного анализа? Допустим, что классификация состоит в вычислении некоторого прогностического индекса у и сравнении его с заданным порогом с. Объект относят к первому классу, если у<с, ко второму, если у>с. Прогностический индекс – это обычно линейная функция от характеристик рассматриваемых объектов. Другими словами, от координат векторов, описывающих объекты. Возьмем два значения порога с1 и c2. Если пересчет на модель линейного дискриминантного анализа обоснован, то, как можно показать, "прогностические силы" для обоих правил совпадают: Пусть
Теорема 3 [47]. Если истинные прогностические силы двух правил диагностики совпадают, то при при всех х
где ;
Из теоремы 3 вытекает метод проверки рассматриваемой гипотезы: при выполнении неравенства
она принимается на уровне значимости, асимптотически равном Пример 3. Пусть данные примеров 1 и 2 соответствуют порогу с1. Пусть порогу с2 соответствуют κ’ = 0,95 и λ’ = 0,70. Тогда в обозначениях теоремы 3 κ1 = 0,90, κ2 = 0,05, λ2 = 0,10, λ3 = 0,70. Далее d*(c1) = 2,12 (пример 1), d*(c2) = 2,17, T(κ1, κ2) = 2,22, T(λ3, λ2) = 0,89. Гипотеза о совпадении прогностических сил на двух порогах принимается на уровне значимости α = 0,05 тогда и только тогда, когда
т.е. когда
Так, гипотеза принимается при m = n = 1000 и отвергается при m = n = 5000. Подходы к построению прогностических правил. Для решения задач диагностики используют два подхода – параметрический и непараметрический. Первый из них обычно основан на использовании того или иного индекса и сравнения его с порогом. Индекс может быть построен по статистическим данным, например, как в уже упомянутом линейном дискриминантном анализе Фишера. Часто индекс представляет собой линейную функцию от характеристик, выбранных специалистами предметной области, коэффициенты которой подбирают эмпирически. При этом качественные характеристики тем или иным способом «оцифровываются», их градациям искусственно приписывают численные значения. Непараметрический подход связан с леммой Неймана-Пирсона в математической статистике и с теорией статистических решений. Он опирается на использование непараметрических оценок плотностей распределений вероятностей, описывающих диагностические классы. Обсудим ситуацию подробнее. Математические методы диагностики, как и статистические методы в целом, делятся на параметрические и непараметрические. Первые основаны на предположении, что классы описываются распределениями из некоторых параметрических семейств. Обычно рассматривают многомерные нормальные распределения, при этом зачастую принимают гипотезу о том, что ковариационные матрицы для различных классов совпадают. Именно в таких предположениях сформулирован классический дискриминантный анализ Фишера. Как известно, обычно нет оснований считать, что наблюдения извлечены из нормального распределения [6, раздел 4.1]. Поэтому с прикладной точки зрения более корректными, чем параметрические, являются непараметрические методы диагностики. Исходная идея таких методов основана на лемме Неймана-Пирсона, входящей в стандартный курс математической статистики. Согласно этой лемме решение об отнесении вновь поступающего объекта (сигнала, наблюдения и др.) к одному из двух классов принимается на основе отношения плотностей f(x)/g(x), где f(x) -плотность распределения, соответствующая первому классу, а g(x) - плотность распределения, соответствующая второму классу. Если плотности распределения неизвестны, то применяют их непараметрические оценки, построенные по обучающим выборкам. Пусть обучающая выборка объектов из первого класса состоит из n элементов, а обучающая выборка для второго класса - из m объектов. Тогда рассчитывают значения непараметрических оценок плотностейfn(x) и gm(x) для первого и второго классов соответственно, а диагностическое решение принимают по их отношению. Таким образом, для решения задачи диагностики достаточно научиться строить непараметрические оценки плотности для выборок объектов произвольной природы. Методы построения непараметрических оценок плотности распределения вероятностей в пространствах произвольной природы рассмотрены в разделе 2.5. Методы классификации - одна из наиболее обширных частей нечисловой статистики как области прикладной статистики. В настоящем разделе рассмотрены лишь наиболее важные вопросы, относящиеся к этим методам.
|
||
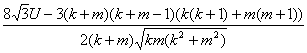
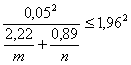 ,
,